《烈幻入》背后的Ren'py
楔子
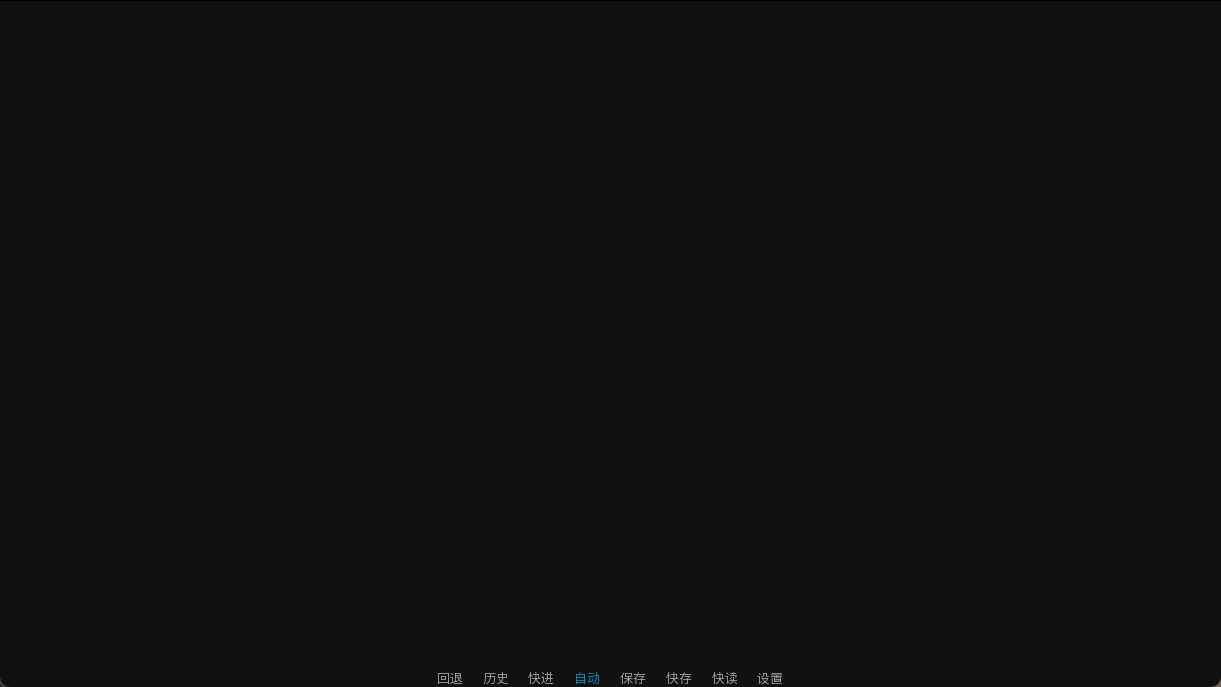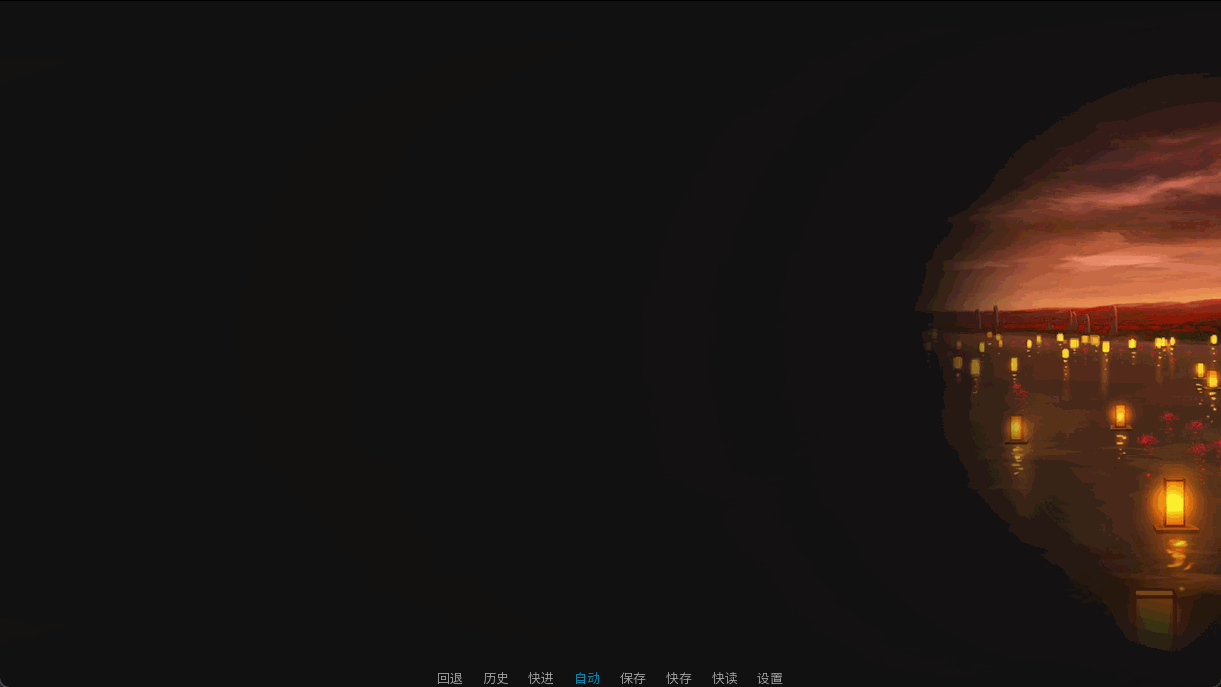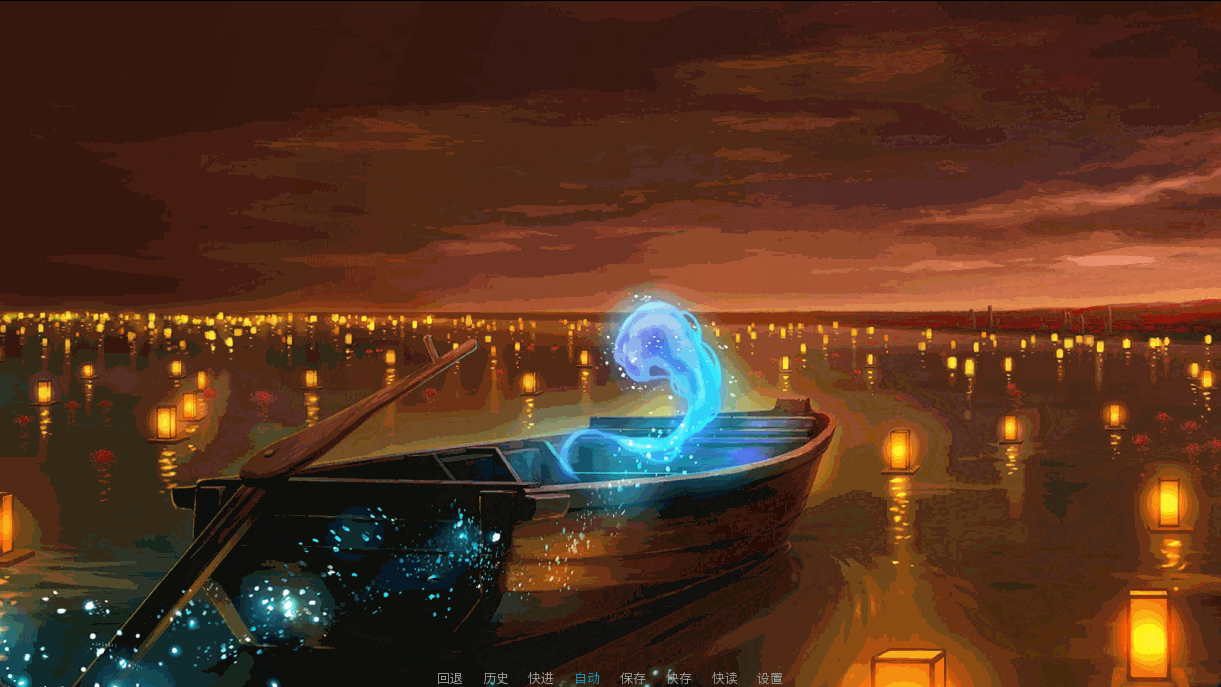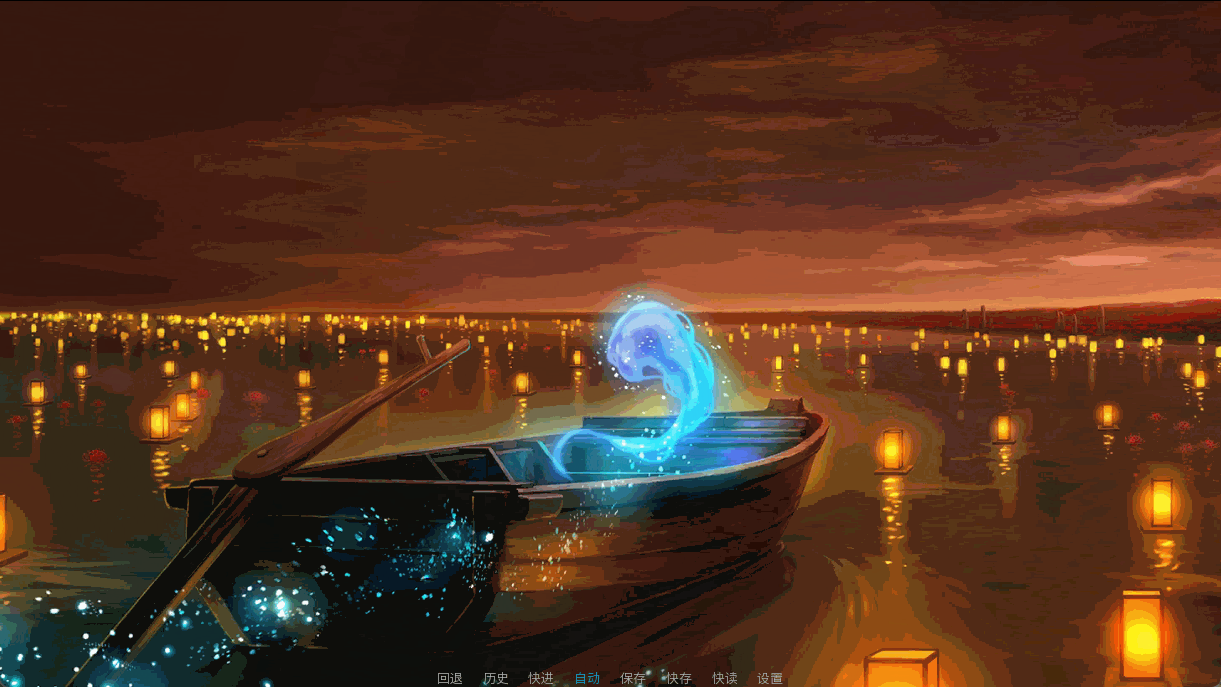
想不到竟然有机会写一篇renpy的“教程”。打引号是因为,虽然被讲说是教程,但完全达不到教程的水准——最初的我是为了练习renpy而写的,于是摘了《烈海王似乎打算在幻想乡挑战强者们的样子》(下称烈幻入)的一段来作为练手。就像学前端就要找个网页抄一样,我也找了些东西来练习renpy的各种功能。然而没想到,做着做着,王子海皇笔下的角色竟然在我脑袋里活了起来,于是我当即写了一篇的量(也就是虹龙洞前置回),然后向王子海皇申请能不能发在b站上——这也就是我的起点了。
那几期视频的简介都很长——因为途中真的有相当多的感悟和体会。三年过去,我再重复一遍实在是显得过于煽情了。但是当年的喜悦仍然滋味未减,因为,能够做自己喜欢做的事情真的是一件非常高兴的事情。虽然我本人做视频是仅仅是为了自己开心,但却能够得到大家的支持,尤其是听到像是“本来以为是小短片结果是剧场版”的评价时,内心还是收到了充实感。
然而同时,我也意识到,我写得东西实在是不够好,能实现的东西相较起脑海的里的逊色不少,脑海里的东西相较起王子海皇的文笔更加逊色一筹,这是我唯一的遗憾。今天既然写这篇文,算是一个契机,虽说很想再续一篇视频,但遗恨想象力的匮乏,只能万愿将来再能有某天能写出让大家都开心的作品来。但是在那之前,我想把我的代码稍作整理,记下心得,以备后用。然后就变成了——那样,不就也可以分享出来了吗?这并非教程,因为我的代码里充分暴露了我作为初学者蹒跚学步的弯路,在时隔三年后再在蜣螂堆成的代码上叠床架屋,无疑是自讨苦吃。但稍作整理或许能帮助到一些和我一样刚刚接触renpy的人——包括我自己。
楔子太长了,该赶紧步入正题了。
renpy的基础
大多数内容其实都可以在文档里找到,并找到更细致的描述——文档是最重要的。虽然文档的检索功能一言难尽,但把文档细细看完的话,一定能收获良多吧。文档更加全面且细致,笔者这里记录的只是半生不熟的一些心得,椎轮大辂,我们先从简单的东西开始。
脚本标签
我最早是照着馆长海皇的视频开始下手的,我们就以此开始介绍renpy的基础吧。
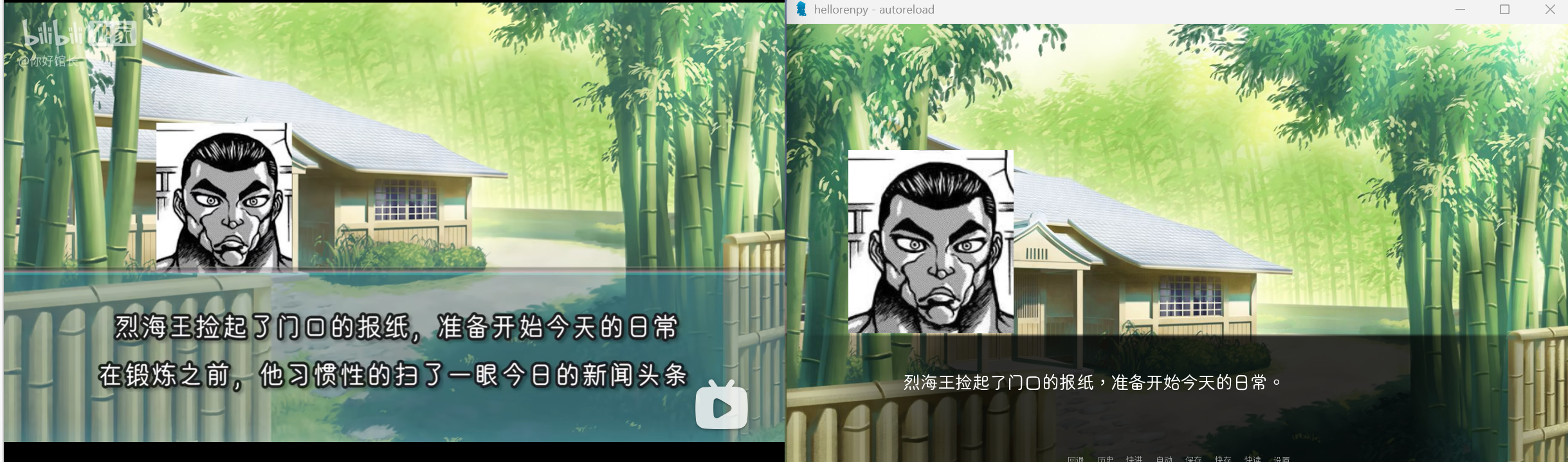
renpy的脚本相当简单,我们需要一个start的label,之后,直接打字符串,就可以开始在游戏里显示对话了。
1
2
3
label start:
"烈海王捡起了门口的报纸,准备开始今天的日常。"
"在锻炼之前,他习惯性地扫了一眼今日的新闻头条。"
label是一个相当好理解的东西,剧本是自上而下执行的,label会标记一个位置,之后可以用jump或者call来跳到这里。jump是类似goto一样的语法,在编程语言中因为破坏了程序的结构,所以一般是不推荐的,但游戏中,要求跳到某一个地方的需求还是相当广泛的。call则简单了,它会像函数一样(压栈)调这个label,并在return后返回原位置。如果要组织章节,那就把所有章节挨个call一遍即可。
1
2
3
4
label start:
call chapter1
call chapter2
call chapter3
标签是可以带参数的,这让标签像函数一样。另外,到文件的末尾也算是return。我在不厌其烦地复制了好多遍之后,终于把投骰子的地方封装成了label。
1
2
3
4
5
6
7
8
9
label start:
"烈使用了烈车拳!"
call fail_message("敌人太强了") from start_call_fail
"从扎马步重新练起吧。"
return
label fail_message(why):
"因为[why],烈倒下了!"
return
start是一个特殊的标签,它是剧本的入口。除此之外还有quit、after_load、main_menu等。main_menu会显示主菜单,像我制作烈幻入视频时,其实不需要主菜单,所以可以在main_menu里直接返回,跳过主菜单。
renpy推荐在call后接from,便于调试。(不过renpy好像有一键添加from,所以我就不加了)。
变量
renpy里当然有变量系统,这就涉及到我们要在renpy里写python。在对话里使用[变量名]可以显示变量的值。
需要玩家输入的的话,可以使用renpy自带的input函数。
1
2
$ player_name = renpy.input("你的名字是?")
"[player_name]哟,去打败魔王,拯救世界吧。"
1
2
3
4
5
6
7
8
9
10
11
init -5 python:
import random
label start:
"你投了一个骰子:"
$ dice_value = random.randint(1, 6)
"得点为 [dice_value]。"
"你投了20个骰子,得点总和为:"
python:
dice_sum = sum(random.randint(1, 6) for _ in range(20))
"[dice_sum]。"
python:是调用python代码的起手式,在里面你可以自由地写代码了。$是单行python代码的简写形式。
有时候你需要一些在剧本开始前(初始化阶段)就运行的代码,init python后的语句就是如此。可以再这里定一些类或者函数。-5是优先级,越低越先执行。没有就是默认0。
define用于定义常量,不应修改常量。default用于定义变量的默认值,比直接用python的好处在,游戏会维护后面的变量,这样能保证不会因为重开游戏或者存档读档变量不一致产生奇奇怪怪的问题。
1
2
define DICE_SIDES = 6
default dice_count = 20
python和$是随着脚本(Script)进行而执行的,default在剧本开始前执行。而初始化(Init)阶段要再之前:init python、define、image、transform、style、screen在初始化阶段中按顺序执行。导入文件系统的图片在0优先级,所有image在500优先级,其他语法都默认0优先级。可以用init offset来设置优先级,效果保持到遇到下一个init offset或文件的末尾。例如下面的脚本执行后,foo的值最终是2。
1
2
3
4
5
init offset = 2
define foo = 2
init offset = 1
define foo = 1
比初始化阶段更早期的是脚本处理(Early)阶段,这一段的代码由python early引导,用户可以在这里自定义一些renpy语法以及缓动函数。
角色
1
2
3
4
5
define r = Character("烈", image="烈", who_color="#fff", who_outlines=[(2, "#000", 0, 0)])
define nvl_r = Character("烈", image="烈", who_color="#fff", who_outlines=[(2, "#000", 0, 0)], kind=nvl)
default chimata_name = "千亦"
define chimata = DynamicCharacter('chimata_name', image='chimata', what_outlines=[(1, "#04afff", 0, 0)], what_color = "#f8d6f4", who_color="#774695", who_outlines = [(1, "#ccc", 0, 0)])
对话框里显示的话其实都是某个角色说出的话,我们叫做say语句。角色是Character()构造出的实例,可以设置名字、类型、图片等等。这里贴一下实现。动态角色对象允许在剧本里动态地改变名字,每次对话前,DynamicCharacter都会计算name_expr的值并修改名字。
1
2
3
4
5
6
7
8
9
def Character(name=NotSet, kind=None, **properties):
if kind is None:
kind = renpy.store.adv
kind = getattr(kind, "character", kind)
return type(kind)(name, kind=kind, **properties)
def DynamicCharacter(name_expr, **properties):
return Character(name_expr, dynamic=True, **properties)
这里的adv是最基础的角色类ADVCharacter,另一种模式是NVL模式,对应的类是其子类的NVLCharacter。ADV就是通常的一个角色说一句话的格式,NVL则是把整个屏幕都占着的对话模式,一行一行地刷着也特别有感觉。nvl clear可以清空所有nvl内容。
1
2
3
4
5
6
7
8
9
10
11
12
nvl_narrator "原理十分简单。\n利用生命力的技术……他在过去的一段时间内经常使用。"
nvl_narrator "急救技术。\n汇聚大量的生命力,令自身在极度不利的状况下起死回生。"
nvl_narrator "那么,反其道而行之。\n如果将这份精炼出的强大生命力,在一开始的时候就就直接使用。"
nvl_narrator "并不是集于拳上而是分散到全身……\n并不是用于治疗而是应用于战斗……"
nvl_narrator "能够依靠的经验是存在的。\n四季异变时在他身后打开的生命力之门,那令他各位活跃的状态就是他可以借鉴的对象。"
nvl_narrator "于是武者开始尝试。"
nvl clear
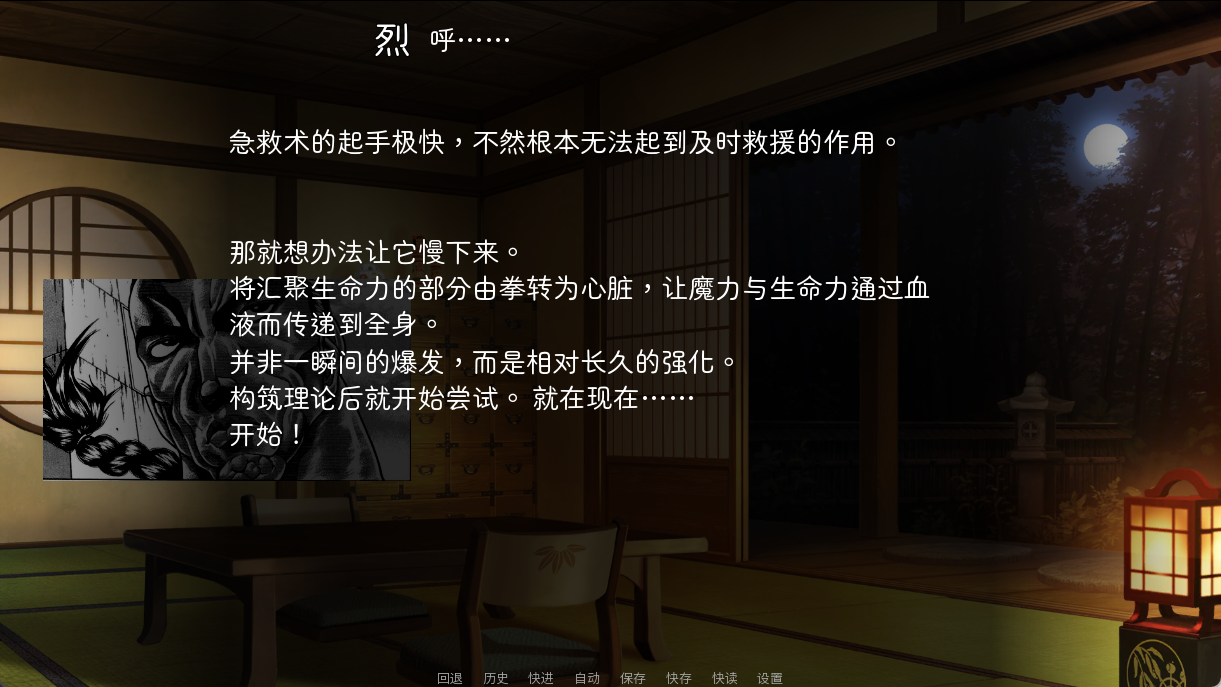
nvl_r "呼……"
nvl_narrator "急救术的起手极快,不然根本无法起到及时救援的作用。"
nvl_narrator "那就想办法让它慢下来。\n将汇聚生命力的部分由拳转为心脏,让魔力与生命力通过血液而传递到全身。"
nvl_narrator "并非一瞬间的爆发,而是相对长久的强化。\n构筑理论后就开始尝试。就在现在……\n开始!"
nvl clear
注意到,有些文本是没有加角色直接说出来的,不带角色的对话其实也会由一个叫做narrator的角色来发出,如果想要修改旁白的样式,就要修改narrator。下面的源码也能看到centered和vcentered这些角色的定义。(我当时并不知道还自己定义了个centered,唉~)
1
2
3
4
5
6
7
8
9
10
11
12
13
init -1400 python:
# The default narrator.
_narrator = Character(None, kind=adv, what_style='say_thought')
adv_narrator = _narrator
# Centered characters.
centered = Character(None, what_style="centered_text", window_style="centered_window", statement_name="say-centered")
vcentered = Character(None, what_style="centered_vtext", window_style="centered_window", statement_name="say-centered")
init 1400 python:
if not hasattr(store, 'narrator'):
narrator = _narrator
除此之外还有一个角色叫做extend,它会动态地获取上一个说话人,并在在原有对话中再加一行对话。可以用于更改其他内容后继续对话。比如我想在两句话之间加一个音频播放,换一张角色的表情,又或者让屏幕震动。
1
2
3
4
5
6
7
k "对藤原妹红进行四次直☆接☆攻☆击。"
k "每一次攻击宣言都会让聚集夜莺的攻击力上升500,你所受到的伤害依次是——"
k "2500点!" with vpunch
extend "{size=+6}3000点!!{/size}" with vpunch
extend "{size=+12}3500点!!!{/size}" with vpunch
extend "{size=+18}4000点!!!!{/size}" with vpunch
k "赢了,真是一次有趣的决斗啊!"

1
2
3
4
5
6
ak "我在和皮克君的每日训练中掌握了高超的登山技巧,这种程度没问题!\n"
show 阿求:
ease 0.6 yoffset 30
pause 0.4
ease 0.6 yoffset 0
extend "能办到这些也多亏了你提供的训练计划,谢谢了。"
最后我们说说角色的一些属性吧:
- name:角色名。
- kind:角色类型,可以以把另外一个角色的属性当做默认值,来构造新角色。比如之前的adv和nvl。
- image:传入一个字符串,renpy会自动在文件系统中寻找以image开头的一系列图片,我们一会讲到图片时再细说。
- dynamic:如前所述,为真时说明是动态角色。
- what_prefix、what_suffix、who_prefix、who_suffix:这些属性设置了台词或角色名的前缀和后缀。比如如果你希望所有角色在说话时自动加引号,或者某个角色在每句话的末尾都自动加“喵”就可以用这个功能。(不过由于我们烈幻入的剧本相当固定,我没有使用这些功能)
- callback:对话事件调的回调函数,详情参考
- 以who_、what_、window_开头,后接各种样式的特性。这里我拿来设置角色名和对话的颜色和边框,也就是color和outlines,outlines的元组参数分别是(尺寸、颜色、x偏移、y偏移)。
1
2
define m = Character("妹红", image="妹红", what_outlines=[(2, "#FA2946", 0, 0)], who_color="#FA2946")
define k = Character("辉夜", image="辉夜", what_outlines=[(2, "#000", 0, 0)], what_color="#f69897", who_color="#f69897", who_outlines=[(2, "#000", 0, 0)])
三年前我一直有个遗憾,那就是没有给千亦搞一个彩虹色的轮廓线,这两天我在查资料时发现Ren’Py在8.3版本更新了文本着色器!我先留一个参考链接和文档,后面我会稍微详细说说的。
- ctc:也就是所谓的“点击继续”(click to continue),就是很多游戏里对话显示完毕后,右下角会出现的提示玩家点击以继续的东西。在《命运石之门》里是一个像是坏掉的齿轮一样的东西,《逆转裁判》里的话是向右的继续箭头,不过也有许多游戏没有这样的箭头。我们的载体是视频,不需要提示玩家点击屏幕,所以便没有使用。
- ctc_position:默认是
"nestled",ctc会在文本后面,如果想要设置在右下角,可以用"fixed",位置由ctc的样式决定。 - screen:界面,我们后述。
在对话里是可以临时修改这些属性的。
1
ksz "她看上去好可怜,我刚刚是不是该输掉的啊……" (name="小铃(小声)")
文本标签
现在来看一下如何给对话文本添加样式。首先是转义字符。
\"双引号\'单引号\\反斜杠\n换行\空格\%或%%百分号[[左方括号{{左花括号
任意长的空白字符都会变成一个空格,如果想要保留空白字符,可以使用\转义。你可能会像python一样使用三引号,但是三引号里的一个换行符也会被当做空格,更多的换行符则会分割整段话为多个say语句,这倒是方便我们。下面两种写法的效果是一样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
k "可在这一成不变的幻想乡中,新事物总意味着骚动。"
k "在他所不知晓的地方,这些轻巧又便宜的能力卡牌以超乎想象的速度开始在幻想乡的居民之间流通。"
k "大家纷纷猜测着,这是某位大妖怪心血来潮的恶作剧?是又一种被外界遗忘之物?而不管原因如何,此地的住民们总习惯对这些新奇的事件
冠以统一的称呼。"
k "于是,就在这个夏天的开头。\n有关于金钱、交易与卡牌的异变开始了。"
k """可在这一成不变的幻想乡中,新事物总意味着骚动。
在他所不知晓的地方,这些轻巧又便宜的能力卡牌以超乎想象的速度开始在幻想乡的居民之间流通。
大家纷纷猜测着,这是某位大妖怪心血来潮的恶作剧?是又一种被外界遗忘之物?而不管原因如何,此地的住民们总习惯对这些新奇的事件冠以统一的称呼。
于是,就在这个夏天的开头。\n有关于金钱、交易与卡牌的异变开始了。"""
下面是文本标签。
1
2
3
4
5
6
7
8
9
10
11
12
13
k """{b}粗体{/b} {i}斜体{/i} {s}删除线{/s} {u}下划线{/u}
{color=#f00}红色{/color} {outlinecolor=#0f0}绿色边框{/outlinecolor} {alpha=0.5}半透明{/alpha}
200像素的空格{space=200}{size=30}30号字{/size} {k=5}5像素的字间距{/k}
{font=SourceCodePro-Regular-12.ttf}change the font{/font}
Ruby:{rb}東 京{/rb}{rt}とうきょう{/rt}
一张{image=mallet}{alt}万宝槌{/alt} {noalt}<3{/noalt}{alt}heart{/alt}
{cps=*2}两倍速显示{/cps}
这里说一下alt,alt是替代文本的意思。在网页中如果当图片无法显示时,alt会显示在图片的位置,也可以用于显示图片的说明。在Ren’Py中,alt用作TTS系统的朗读文本。比如这里就会把图片读成“万宝槌”,把”<3”读成“heart”。
需要赋值的标签里,可以用加减乘除,表示在原有基础上的操作,比如cps=*2就表示播放速度翻倍。
1
2
3
4
5
k "玩家不点击也会立马跳到下一句{nw}"
k "读到我停顿两秒钟{w=2.0},停顿结束。"
k "读到我暂停两秒钟并换行。{p=2.0}暂停结束。"
k "此前内容直接显示{fast},之后内容继续打出。"
k "此后内容不再显示。{done}不再显示的内容"
众所周知,Ren’Py是个游戏引擎,是需要玩家点击才会进入下一句话的(大嘘)。那么这里的若干标签是控制和玩家的交互的。譬如在需要停顿的地方停顿。done出现后,这一句话不会在历史信息里显示,所以可以用于在句子读到一半时出去做什么事,之后用fast接同样的一句话,并且在历史记录里也看不出破绽:
1
2
3
4
5
6
"【1d60: 】分钟后,{w=2.0}{done}"
"【1d60:5】分钟后,{fast}烈海王以最快速度飞到了人里。"
suwako 生气 "早苗,你怎么能这样对待你的神明,\n又不是什么大不了的事——{w=0.2}{nw}{done}"
show sanae 阴险
suwako 惊讶 "早苗,你怎么能这样对待你的神明,\n又不是什么大不了的事——{fast}咿呀!"

有些时候我们可能会需要自定义一些文本标签,譬如我们可能常用红色作为骰子的颜色,那么就可以定义一个标签:
1
2
3
4
init python:
def red_tag(tag, argument, contents):
return [(renpy.TEXT_TAG, u"color=#f00")] + contents + [(renpy.TEXT_TAG, u"/color")]
config.custom_text_tags["red"] = red_tag
这里的“red_tag”是自定义文本标签函数,tag是其自身,argument是本标签的参数,contents则是其包裹的内容(如果是自闭合文本标签,则不写这个参数)。包裹的内容是一个内容元组的列表。内容元组是(type, value)的形式,type是内容类型,value是内容值。type可以是以下值:
renpy.TEXT_TEXT:文本renpy.TEXT_TAG:文本标签,不包含花括号renpy.TEXT_PARAGRAPH:换行,第二部分始终为空。renpy.TEXT_DISPLAYABLE:嵌入文本的可视组件
以为例:
1
k "{red}测试一段文本,\n测试一个换行,{cps=*2.0}测试一些文本标签,{/cps}{image=mallet}{/red}"
得到的是:
1
2
3
4
5
6
7
8
9
contents = [
(renpy.TEXT, '测试一段文本,'),
(renpy.TEXT_PARAGRAPH, ''),
(renpy.TEXT, 'n测试一个换行,'),
(renpy.TEXT_TAG, 'cps=*2.0'),
(renpy.TEXT, '测试一些文本标签,'),
(renpy.TEXT_TAG, '/cps'),
(renpy.TEXT_TAG, 'image=mallet'),
]
那么我们要做的其实相当简单,根据标签的需要,把内容元组列表里需要修改的部分修改掉即可。config.custom_text_tags是所有自定义的文本标签,用标签名作为键,函数作为值。config.self_closing_custom_text_tags是所有自定义的自闭合文本标签。
我们现在写一个自动投骰子的功能吧:。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
label easy_dice(cts, ans, cha=None, clr="#f00", flag=0, contents_append=""):
# cha是要说话的角色 默认是旁白
# cts表示要说的文本 其中用{}表示要填入ans的地方
# flag为1表示大成功 2表示大失败 影响音效
# 如果cts里留的空比ans多一个 且flag为1或2 则会自动填入大成功或大失败
# contents_append表示在骰点出来后,再之后附加显示的内容
window show
python:
if isinstance(ans, int):
ans = (ans,)
alpha_ans = [f"{a}" for a in ans] # 透明的骰点 用于占位
color_ans = [f"}{a}" for a in ans] # 带颜色的骰点
contents_before = cts.format(*alpha_ans, "")
contents_before = contents_before + "{done}"
if flag:
contents_after = cts.format(*color_ans, "{color=%s}%s{/color}"%(clr, "大成功" if flag == 1 else "大失败"))
else:
contents_after = cts.format(*color_ans)
contents_after = contents_after + "{fast}" + contents_append
$ renpy.say(cha, contents_before) # say语句
if flag == 0:
play sound soundDice # 骰子音效
elif flag == 1:
play sound soundSuccess # 大成功音效
else:
play sound soundFail # 大失败音效
$ renpy.say(cha, contents_after) # 等待玩家点击后的第二句say语句
$ del(contents_before)
$ del(contents_after)
$ del(alpha_ans)
$ del(color_ans)
window auto
return
调用方式是:
1
2
3
4
call easy_dice("~这件事发生在烈海王来到幻想乡的第【1230+1d30:{}={}】天~",(22, 1252), cha=centered)
call easy_dice("烈的好奇心【1d100:{}】{}(50以上询问详细情况)",3 , flag=2)
call easy_dice("于是这里过个少女们的同情心【1d70:{}+30={}】(50以上就把钱还回去,基础的同理心+30)", (66, 96), flag=1)
call easy_dice("【1d30:{}】分钟后", 27, contents_append=",一边用治疗术吊着武术家的命一边在迷途竹林中迷路到快发狂的神明大人总算找到了永远亭。")

动画和变换
图片
renpy的资源素材里,图片应该以“标签(tag)+若干属性(attribute)”(也可以没有属性)的格式命名,文件系统images文件夹及其子文件夹中以这个格式命名的图片会自动被加载,例如:

1
2
3
4
5
6
7
show 千亦 闭眼
cmt "都说了我的目的是开设集市而不是赚钱。\n虽说是会受到点“影响”,不过一张卡牌的程度无所谓啦。"
cmt "你当时的建议让我少走了很多弯路哦,这个就算是一点谢礼。\n再说我也没什么好送礼物的朋友,白狐又不需要这个……"
show 烈 疑惑
r "(白狐是谁啊?)\n那我就不客气地收下了。\n我也能理解,你的社交力的确是到了可称之为灾难的级别。"
show 千亦 腹黑
cmt "闭嘴你这天邪鬼。"
显示图片时,相同标签的图片会互相替换,一行代码就可以替换表情。

上面的代码和下面是等效的(因为烈和千亦这两个角色都各自定义了image)。
1
2
3
4
cmt 闭眼 "都说了我的目的是开设集市而不是赚钱。\n虽说是会受到点“影响”,不过一张卡牌的程度无所谓啦。"
cmt "你当时的建议让我少走了很多弯路哦,这个就算是一点谢礼。\n再说我也没什么好送礼物的朋友,白狐又不需要这个……"
r 疑惑 "(白狐是谁啊?)\n那我就不客气地收下了。\n我也能理解,你的社交力的确是到了可称之为灾难的级别。"
cmt 腹黑 "闭嘴你这天邪鬼。"
所谓的标签是类似标识符一样的东西,而属性是可以有多个并且是无关顺序的,图片在show时,会尽可能地匹配标签,例如,如果我们定义了以下图片:
1
2
3
4
5
n 白天 腹黑
n 白天 笑
n 夜晚 腹黑
n 夜晚 笑
n 纯黑
在show的时候,会有如下结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
show n 白天
"找不到图片"
show n 腹黑
"n 白天 腹黑"
show n 夜晚
"n 夜晚 腹黑"
show n 笑
"n 夜晚 笑"
show n 腹黑 白天
"n 白天 腹黑"
show n 纯黑
"n 纯黑"
show n 笑
"找不到图片"
hide n
"图片销毁"
去除某个属性可以在属性前加减号-。
show语句用于显示图像,hide语句用于移除图像、scene是清空图像后显示一张图像(比如用于开一新篇章时换背景)。
以下是show语句可以使用的特性:
as图像标签别名,可以让同样的图片在屏幕上显示多次而不互相替换at对图片应用若干变换behind后接若干图片标签,表示当前图片应该在那些图片的后面,很方便zorder当想要更精准地控制图片的前后关系时可以使用这个特性,默认是0,数值大的图片会遮挡数值小的图片onlayer图片所绘制的图层,以下是默认的图层:[ ‘master’, ‘transient’, ‘screens’, ‘overlay’ ],一般的图片都显示在master层上。
想要增加新图层,可以使用renpy.add_layer(layer, above=None, below=None, menu_clear=True, sticky=None),下面介绍参数:
- layer:字符串,图层名
- above:字符串,在哪一层之上
- below:字符串,在哪一层之下,above和below不能全为None
- menu_clear:进入游戏菜单时隐藏,并在离开游戏菜单时恢复
如果希望使用更复杂的图片,可以用image定义图像。
1
2
3
4
5
6
image 注意点:
"item/注意点 1.png"
0.25
"item/注意点 2.png"
0.25
repeat

1
2
3
4
5
6
7
8
9
show 注意点:
xzoom -1
xcenter 0.55
ycenter 0.35
zoom 0.75
alpha 0.0
ease 0.2 alpha 1.0
show 千亦 笑
cmt "正是。\n解放龙珠中的能力,将其制作为卡牌,并将卡牌复制,流通。\n负责这些的全都是我哦~"
你可能注意到了这里有大量表述图片位置、大小、甚至是动画的语句,我们把这些称为动画和变换语言(ATL),修改的这些属性我们叫做特性(property)。我们先从简单的开始。
变换特性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
show 千亦 笑:
xcenter 0.5
ycenter 0.5
show 千亦 腹黑 as 千亦2:
xpos 100
ypos 100
xanchor 0.0
yanchor 0.0
show 千亦 眼泪 as 千亦3:
xalign 1.0
yalign 0.0
show 千亦 流汗 as 千亦4:
align (0.0, 1.0)
offset (100, -100)
show 千亦 惊讶 as 千亦5:
xanchor 1.0
yanchor 1.0
xpos 0.9
ypos 0.9

首先是位置,这里是图片常用的左手坐标系,向右为x正方向,向下为y正方向,所以(0.0, 0.0)为图片的左上角,而(1.0, 0.0)为图片的右上角。使用小数表示是百分比,而使用整数表示是像素。可以用x或y来分别设置x和y坐标,也可以用元组来一起赋值。
图片有一个锚点anchor,图片的pos即是把锚点放置在屏幕的某个位置上。例如anchor (0.0, 0.0)和pos (100, 100)即意味着,把图片的左上角,放置在屏幕的(100, 100)像素位置上。anchor默认是(0.5, 0.5),即图片的中心。offset是图片在刚才所有的基础上,再进行的偏移量。offset只使用像素。
renpy还提供了center和align来同时修改anchor和pos,前者将图片中心放置在屏幕的某个位置上,后者图片的某个位置放置在屏幕的同样的位置上。例如xalign 0.0就意味将图片的左边放在屏幕的左边,也就是图片恰好贴着屏幕的左边,而xalign 1.0就意味着图片恰好贴着屏幕的右边。熟练使用锚点和位置的话,无论玩家怎样拖拽窗口的大小,图片也能显示在合适的位置上。
这里注意一点,这些renpy提供的特性和底层实现是两码事,修改特性会修改与之相关联的底层实现,例如center、align都会同时修改锚点和位置,因此这两个同时使用是没有意义的。设置了xalign 0.4 xpos 0.8的效果和xanchor 0.4 xpos 0.8是一样的。
接下来是旋转和伸缩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
show 千亦 笑:
xycenter (0.1, 0.5)
rotate 45
show 千亦 笑 as 千亦2o:
xycenter (0.3, 0.5)
yoffset -200
alpha 0.5
show 千亦 笑 as 千亦2:
xycenter (0.3, 0.5)
yoffset -200
rotate 45
show 千亦 笑 as 千亦3o:
pos (0.5, 0.5)
anchor (0.0, 0.0)
alpha 0.5
transform_anchor True
show 千亦 笑 as 千亦3:
pos (0.5, 0.5)
anchor (0.0, 0.0)
rotate 90
transform_anchor True
show 千亦 笑 as 千亦4o:
pos (0.7, 0.5)
anchor (0.0, 0.0)
alpha 0.5
rotate_pad False
show 千亦 笑 as 千亦4:
pos (0.7, 0.5)
anchor (0.0, 0.0)
rotate_pad False
rotate 135
show 千亦 笑 as 千亦5o:
xycenter (0.9, 0.5)
anchor (0.0, 1.0)
alpha 0.5
transform_anchor True
show 千亦 笑 as 千亦5:
xycenter (0.9, 0.5)
anchor (0.0, 1.0)
zoom 2
xzoom -1
transform_anchor True

可以用zoom来控制图片的大小,也可以用xzoom和yzoom来分别拉伸两个轴。和坐标不一样,这些值是乘在一起的,例如如果设置了zoom是2,xzoom和yzoom也是2的话,图片会被放大4倍。一般我们用xzoom -1来水平翻转一张图片。旋转以顺时针为正,单位用角度。
你可能注意到了,即使你设置了anchor,旋转和缩放的中心依然是图片的中心。如果你希望图片以anchor为中心旋转,需要设置transform_anchor True。那么renpy其实是没有以任意点旋转的方式的(当然你可以把anchor挪到那个位置,再算出挪动的距离,反向加在pos上),要实现这一点的话,就需要一些其他的技巧(比如拼接透明图片,或者直接写python代码)。
旋转里还有一个rotate_pad False,如果设置的话,图片会以“最小尺寸”旋转。与其说是旋转,更像是滑动。让图片动起来更好理解吧,这是完整旋转一周的样子:
1
2
3
4
5
show 千亦 笑:
pos (0.5, 0.5)
anchor (0.0, 1.0)
rotate_pad False
linear 5 rotate 360

其他的一些和尺寸有关的变换特性:
crop:裁剪图片,格式为(x, y, width, height)xsize:缩放的宽度ysize:缩放的高度xysize:xsize和ysize的元组fit:自适应地调整图片的大小,可选模式有"contain":保证界面能装得下图片后尽可能地大,保持宽高比"cover":保证图片完全填充界面,不留缝隙后尽可能地小,保持宽高比"fill":拉伸并完全填充界面"scale-down":和contain类似,但是不放大图片"scale-up":和cover类似,但是不缩小图片
xtile:整数,水平平铺的次数ytile:整数,垂直平铺的次数
这些会调整图片的大小,因而和zoom等特性可以叠加。由此我们可以方便地填充背景,例如这样会得到一个向左缓缓移动的背景,背景尽可能小但是又不会露出缝隙。
1
2
3
4
5
6
scene bg 永远亭 with wipeleft:
fit "cover"
zoom 1.2
yalign 0.65
xalign 0.0
linear 40.0 xalign 1.0
还有些和图形有关的特性:
matrixcolor:矩阵,修改颜色,可以给图片加某种后期风格,后述blur:模糊,数值越大图片越模糊
这些变换特性都可以在对应的文档中找到详细描述。
transform
一遍一遍地设置位置会不会太麻烦了?其实可以把若干ATL语句打包起来,随后用at调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
transform pos(x=0.2, y=0.7):
# 设定位置
anchor (0.0, 1.0)
xcenter x ypos y
transform hop():
# 跳一下
easein 0.1 yoffset -30
easeout 0.1 yoffset 0
show 千亦 笑 at pos(x=0.8), hop:
zoom 1.75
cmt "可以吗?那太好了。\n麻烦给我也来一碟~"

renpy其实内置了一些变换,主要是定义了常用的位置。我们可以在源码中找到这些变换的实现。默认的位置是最下方的中间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
init -1400:
transform reset:
alpha 1.0 rotate None zoom 1.0 xzoom 1.0 yzoom 1.0 align (0, 0) alignaround (0, 0) subpixel False
xsize None ysize None fit None crop None
# These are positions that can be used inside at clauses. We set
# them up here so that they can be used throughout the program.
transform left:
xpos 0.0 xanchor 0.0 ypos 1.0 yanchor 1.0
transform right:
xpos 1.0 xanchor 1.0 ypos 1.0 yanchor 1.0
transform center:
xpos 0.5 xanchor 0.5 ypos 1.0 yanchor 1.0
transform truecenter:
xpos 0.5 xanchor 0.5 ypos 0.5 yanchor 0.5
transform topleft:
xpos 0.0 xanchor 0.0 ypos 0.0 yanchor 0.0
transform topright:
xpos 1.0 xanchor 1.0 ypos 0.0 yanchor 0.0
transform top:
xpos 0.5 xanchor 0.5 ypos 0.0 yanchor 0.0
1
2
3
4
5
6
7
8
9
10
11
12
13
+-----------------------------------------------------------+
|topleft, reset top topright|
| |
| |
| |
| |
| truecenter |
| |
| |
| |
| |
offscreenleft|left center, default right|offscreenright
+-----------------------------------------------------------+
动画
为了让图片动起来,我们需要设置“什么属性以怎样的速度变化到什么值”。比如上面的linear 5 rotate 360就表示,在5秒内,让图片的旋转角度线性地从当前值变化到360。
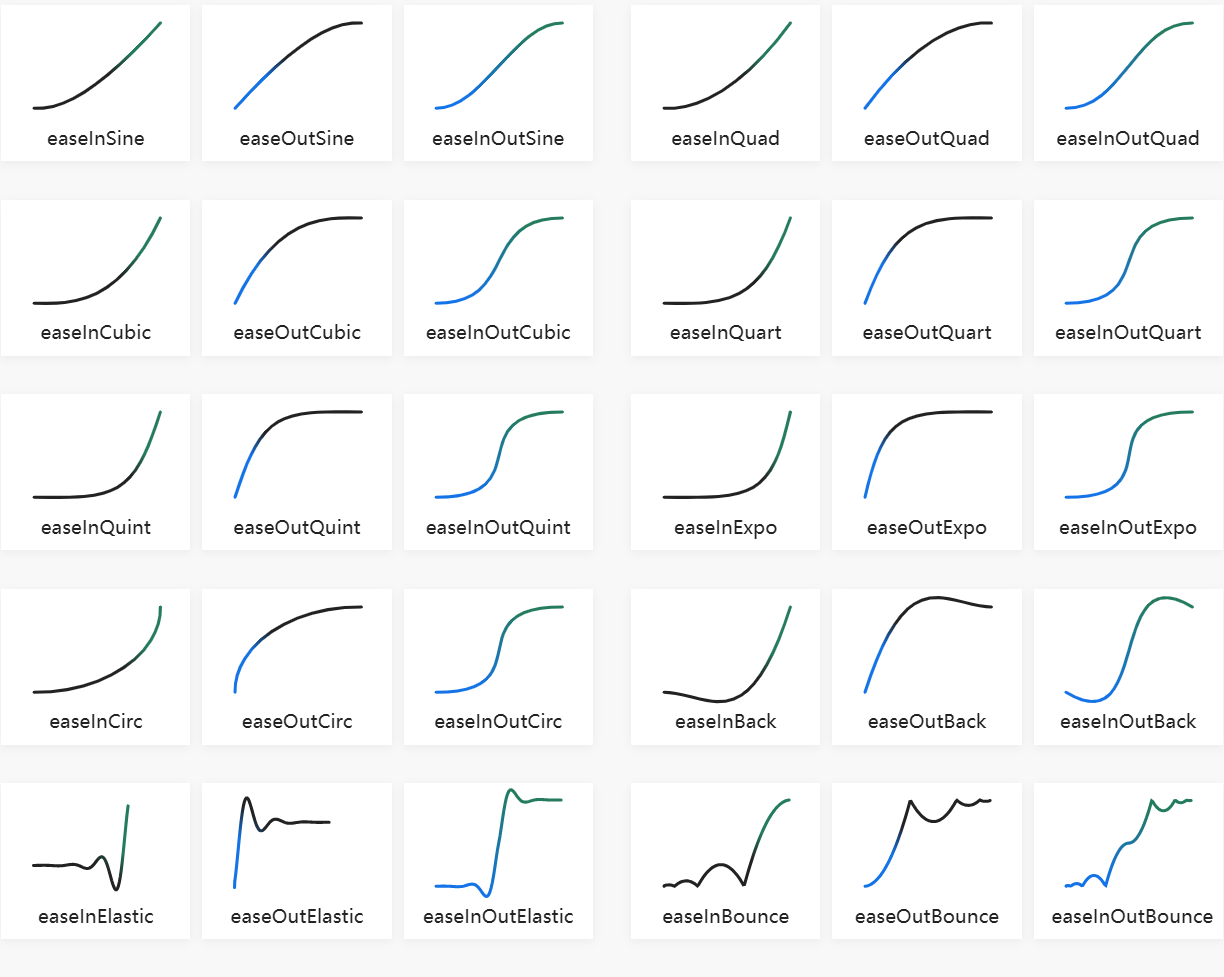
如果我们希望动画先快后慢或者先慢后快,就需要使用其他缓动函数(Easing)了,一般而言,easein是指先快后慢,easeout是指先慢后快,ease则是先慢后快再慢。
1
2
3
4
5
6
7
8
9
10
11
12
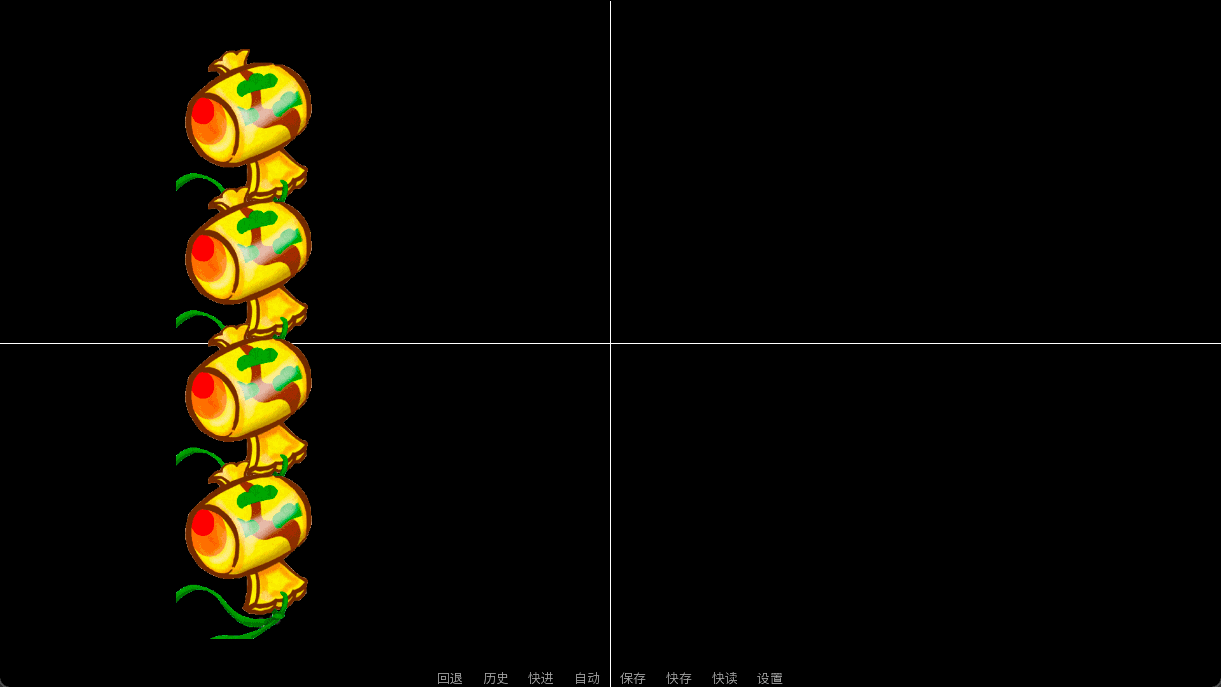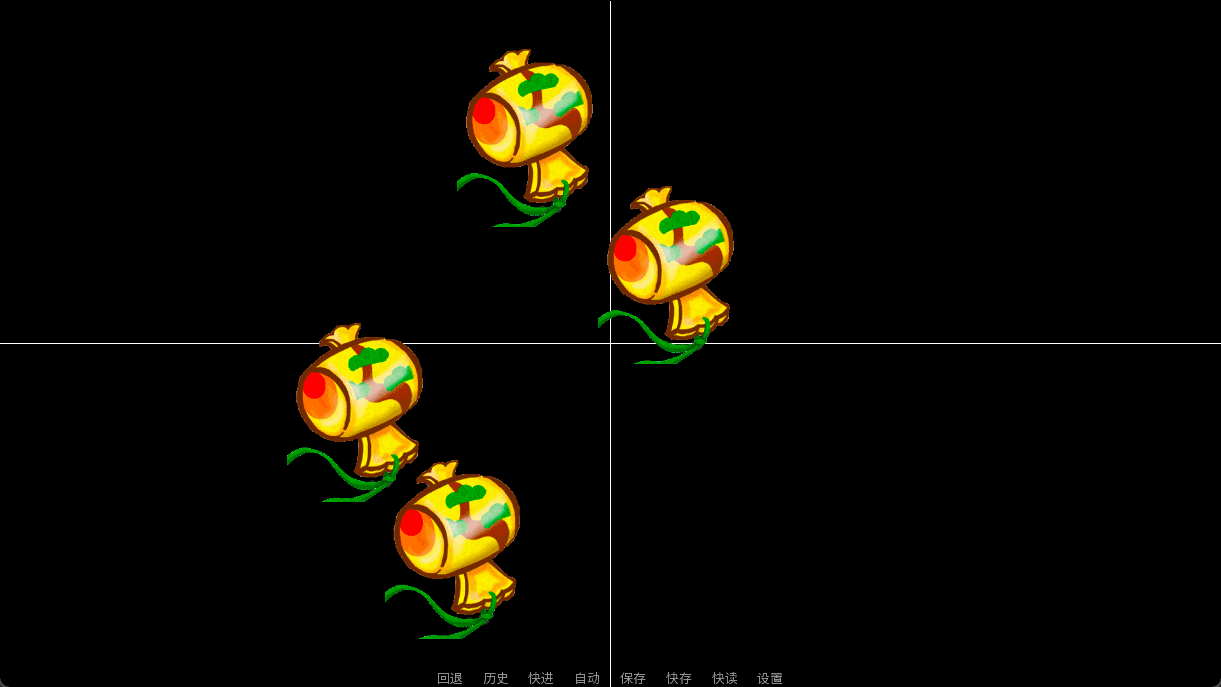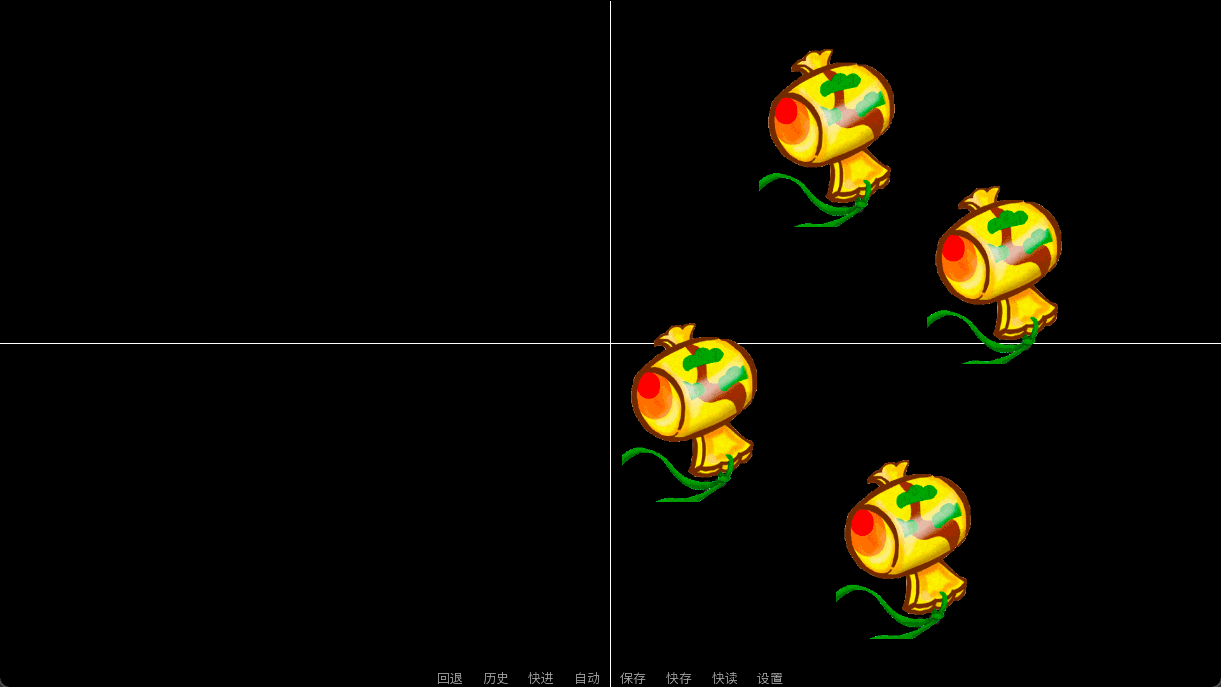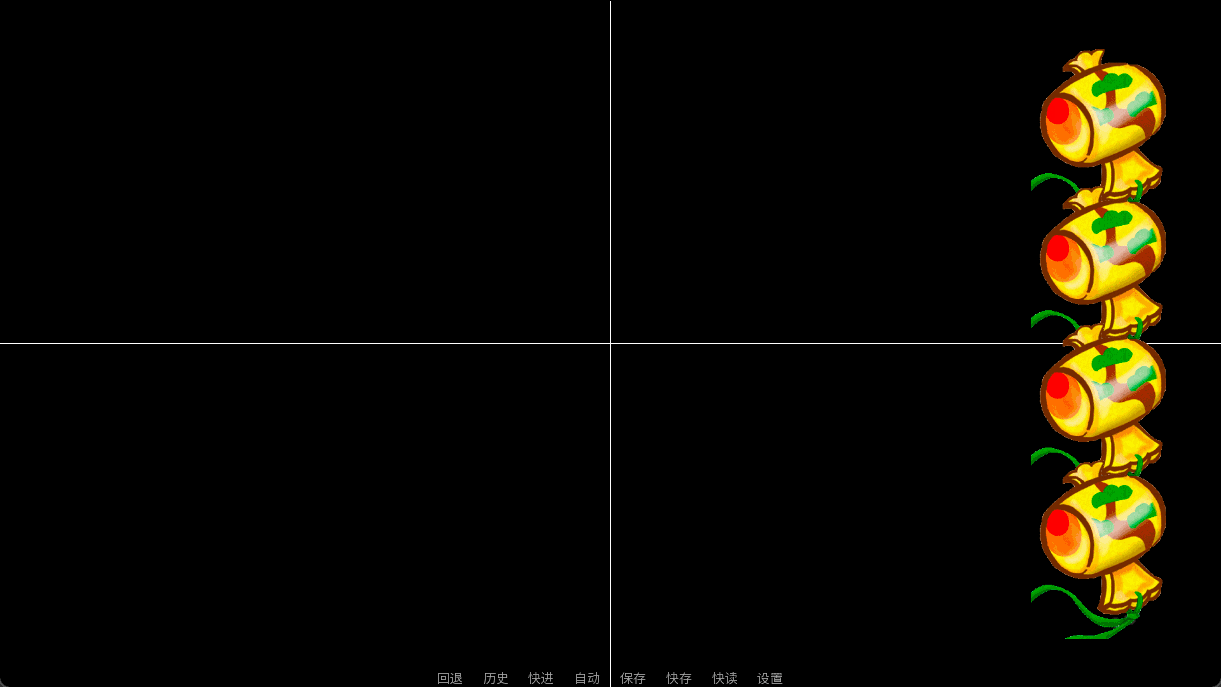
show 万宝槌:
xycenter (0.2, 0.2)
linear 2 xcenter 0.9
show 万宝槌 as 万宝槌2:
xycenter (0.2, 0.4)
easein 2 xcenter 0.9
show 万宝槌 as 万宝槌3:
xycenter (0.2, 0.6)
easeout 2 xcenter 0.9
show 万宝槌 as 万宝槌4:
xycenter (0.2, 0.8)
ease 2 xcenter 0.9
其他缓动函数可以通过翻看文档和常见缓动函数来查找(注意这两个网站的in和out是反着的)。如果你想自定义缓动函数,需要在early阶段写python代码。看过上述两个网站后,不难理解缓动函数是定义在[0,1]上的函数:输入值0表示时间起点,1表示时间终点;输出值0表示起点,1表示终点。所以这些函数都是经过(0,0)点和(1,1)点的。
我们可以在源码中找到这些缓动函数的定义,仿照它不难写出自己的缓动函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
python early in _warper:
from renpy.atl import pause, instant
# pause is defined internally, but would look like:
#
# @renpy.atl_warper
# def pause(t):
# if t >= 1.0:
# return 1.0
# else:
# return 0.0
@renpy.atl_warper
def linear(t):
return t
@renpy.atl_warper
def easeout(x):
import math
return 1.0 - math.cos(x * math.pi / 2.0)
@renpy.atl_warper
def easein(x):
import math
return math.cos((1.0 - x) * math.pi / 2.0)
@renpy.atl_warper
def ease(x):
import math
return .5 - math.cos(math.pi * x) / 2.0
组合这些动画,就可以创造出足够复杂的动画。例如,从左边出现,在中间停顿,然后消失在右边。这三个按顺序执行。
1
2
3
4
5
6
show 万宝槌:
xycenter (-0.2, 0.2)
alpha 0.0
linear 0.5 xcenter 0.5 alpha 1.0
pause 0.5
linear 0.5 xcenter 1.2 alpha 0.0
匀速逆时针旋转,这里旋转到-360后的repeat表示重复执行这一块,后面可以接整数表示次数,如果不接则会一直循环,rotate 0和rotate -360是一模一样的,所以便可以一直旋转。
1
2
3
4
5
6
7
show 万宝槌:
xcenter 0.8
ycenter 0.4
block:
rotate 0
linear 2.0 rotate -360
repeat
我们想做一个平抛运动,那么它在水平方向上就是线性的,竖直方向上就是先慢后快的,具体而言是二次的,也就是quad。parallel表示同时执行:
1
2
3
4
5
6
show 万宝槌:
xycenter (0.2, 0.2)
parallel:
linear 2 xcenter 0.8
parallel:
easeout_quad 2 ycenter 1.2
这是小碗手里一直挥舞的万宝槌:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
show 万宝槌:
xcenter 0.8
ycenter 0.4
alpha 0.0
parallel:
ease 0.5 alpha 1.0
parallel:
ease 0.4 yoffset -50
ease 0.4 yoffset 0
repeat
parallel:
rotate 0
ease 2.0 rotate -360
repeat
animation和function
你可能希望用python来定义更复杂的变换,譬如圆周运动或者贝塞尔插值。这些变换或许拿ATL也写得出来,但是自己拿代码写的话,会有种尽在掌握的感觉(误)。

这里写一个稍微复杂些的例子。我想写一个一秒的动画,一个音符倏地出现,然后降低速度,拐个小弯,透明度降低,而后消失。拐个小弯要怎么拐呢?如果用多段easein和easeout拼接,在拼接处会有很强的违和感,至少我在试了两次之后果断放弃。或许renpy有自己的贝塞尔函数,但是自己实现一个也不难。这是我觉得不错的曲线:
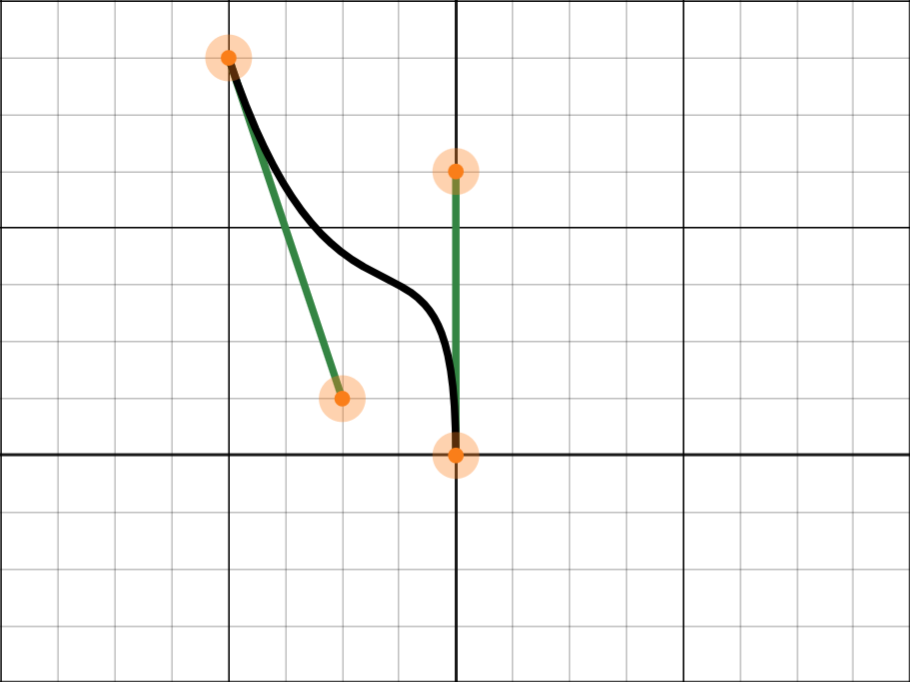
而一个变换函数有三个参数:ATLTransform本身,本函数动画开始的秒数st,以及对象的动画时间轴开始的秒数at(就是说从这个对象一开始就计时,而不是本动画开始)。我们在函数内部修改trans的各项属性,进而操控对象。 函数返回None表示本函数动画执行完毕,会接着跳转到下一行ATL语句。函数返回数字表示下次调用本函数的时间,0表示尽可能快地调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
init python:
def bezier_curve(t, pos_list):
mt = 1.0 - t
x = pos_list[0][0]*mt*mt*mt+3*pos_list[1][0]*mt*mt*t+3*pos_list[2][0]*mt*t*t+pos_list[3][0]*t*t*t
y = pos_list[0][1]*mt*mt*mt+3*pos_list[1][1]*mt*mt*t+3*pos_list[2][1]*mt*t*t+pos_list[3][1]*t*t*t
return (x, y)
def note_move(trans, st, at):
if st > 1.0:
return None
elif st < 0.1:
trans.alpha = 10*st
elif st > 0.75:
trans.alpha = 4*(1-st)
else:
trans.alpha = 1.0
trans.xoffset, trans.yoffset = bezier_curve(st, ((0, 0), (0, -250), (-100, -50), (-200,-350)))
return 0
现在动画已经初具成型。我们再组合上旋转,并反复播放,就完成了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
show 八分音符 as musicnote1:
xcenter 0.65
ycenter 0.4
zoom 0.08
rotate 0
parallel:
function note_move
parallel:
0.5
ease 0.5 rotate 10
repeat
show 八分音符 as musicnote2:
alpha 0.0
zoom 0.08
ycenter 0.32
0.5
block:
rotate 40
xcenter 0.8
parallel:
function note_move
parallel:
0.5
easeout 0.5 xcenter 0.86
parallel:
0.5
ease 0.5 rotate 30
repeat
"土著神在沙发上“kerokero”地笑着。\n她从衣兜里掏出张新的卡牌,在众人眼前一晃,又将其收了起来。"
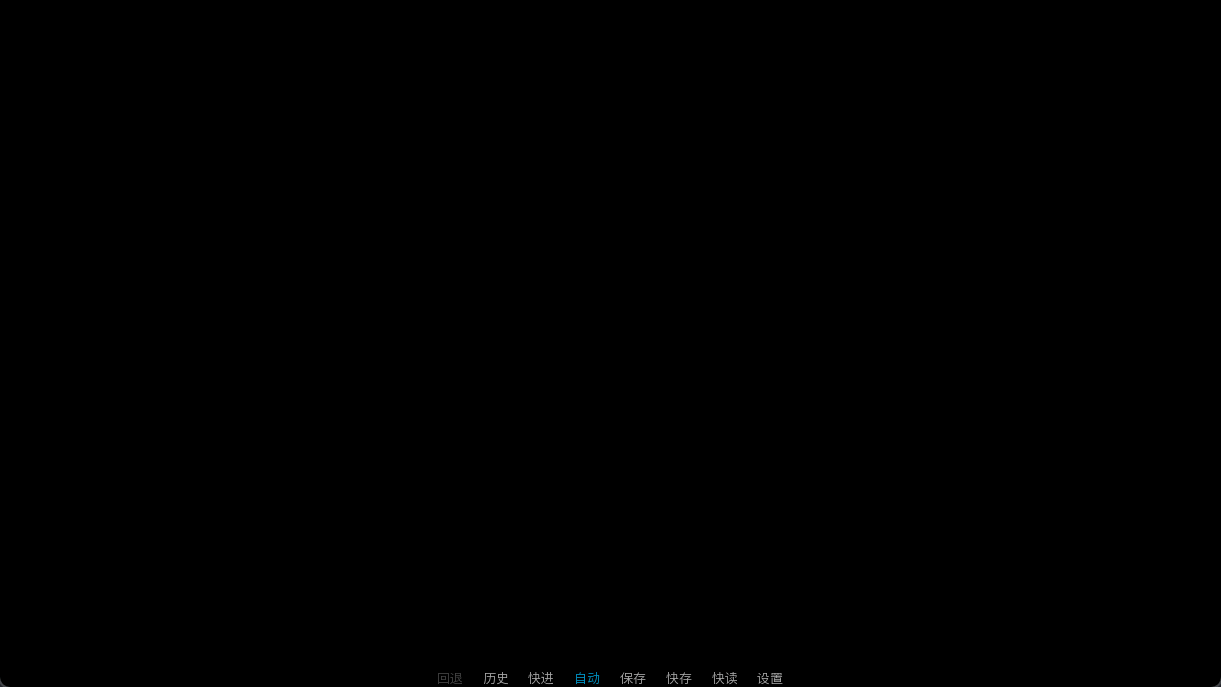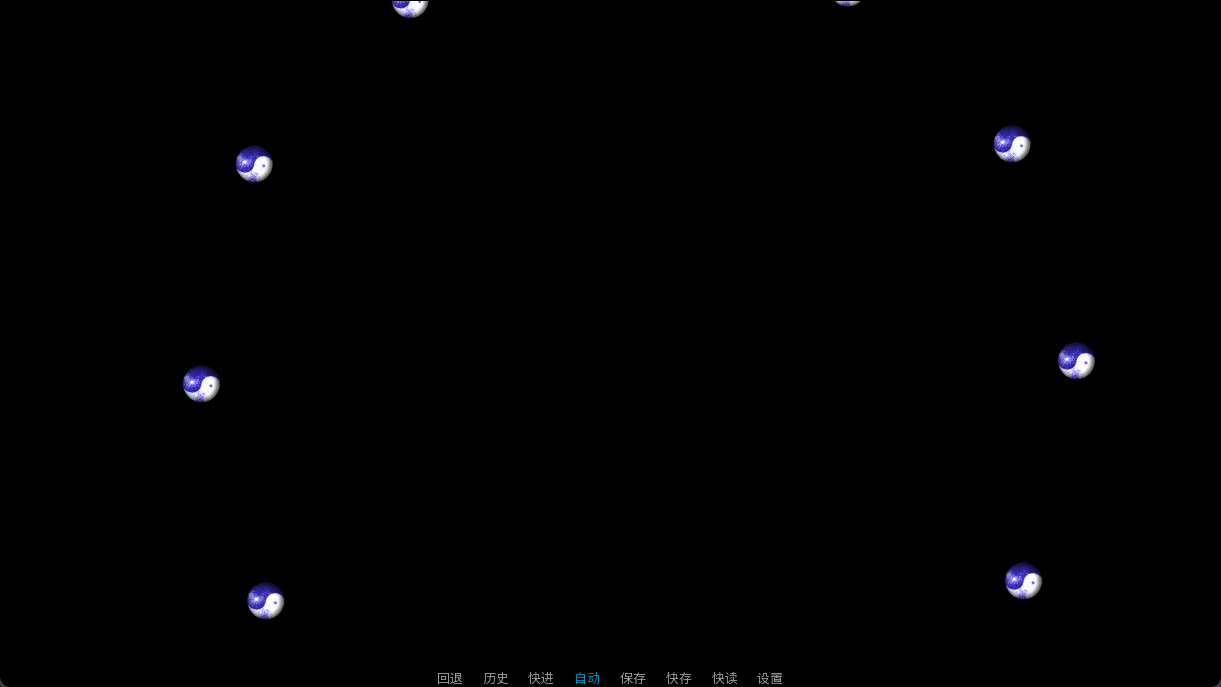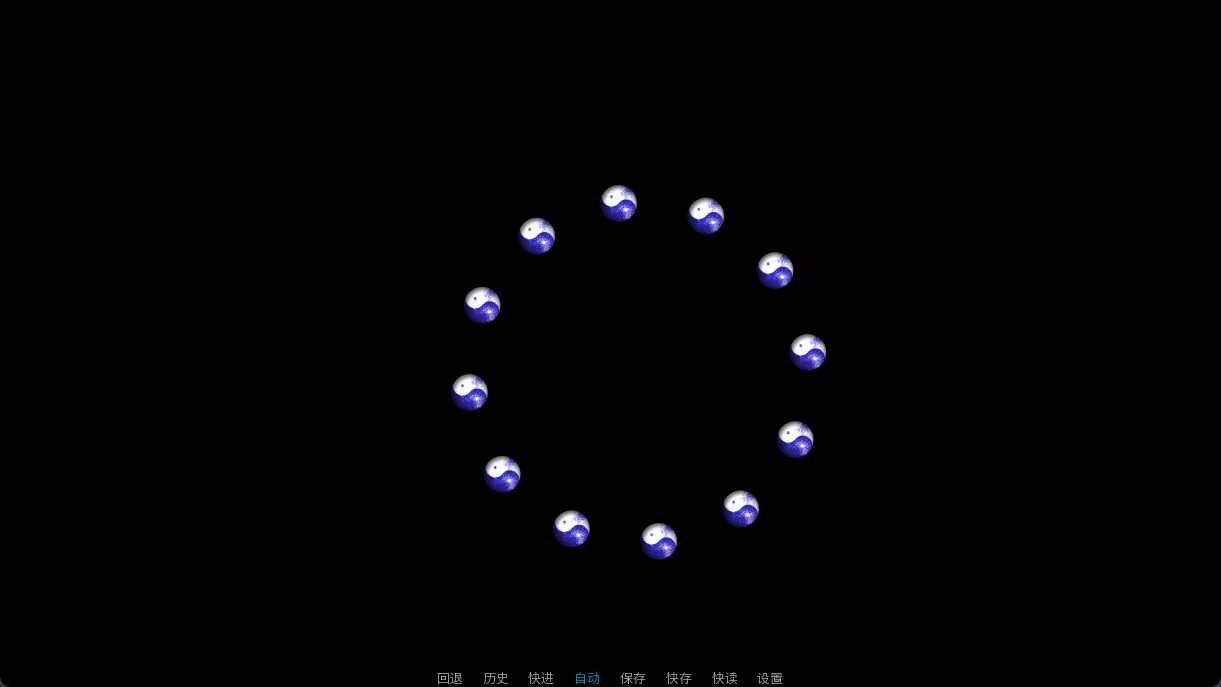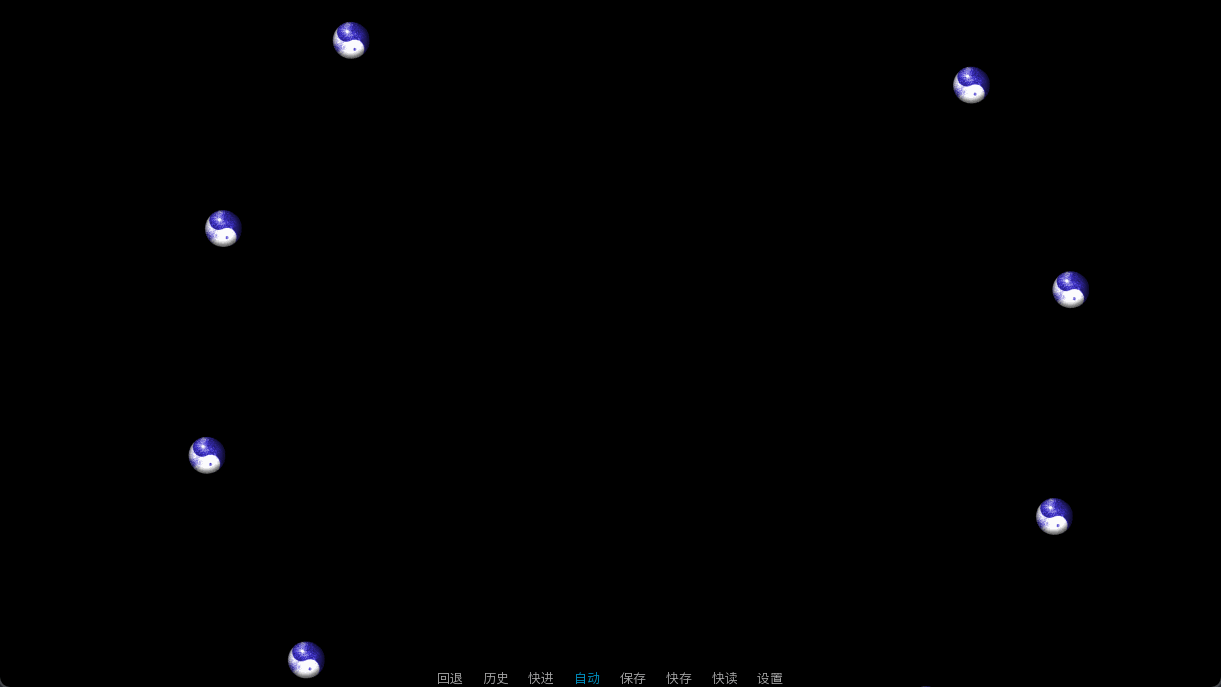
虽然可能并没有人想学,但是我展示一下玉造魅须丸那里的阴阳玉。
我其实并不知道该如何组织这些阴阳玉的行动,我只能使用了最粗暴的办法,每一个阴阳玉show一次。好在,所有Ren’Py语句都有其底层实现,也就意味着show语句也有等效的python语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
renpy.show(name, at_list=[], layer='master', what=None, zorder=0, tag=None, behind=[])
# 等价于show语句
# name 要显示的图像名称
# at_list 作用在图像上的变换 即at特性
# layer 图像所在的图层名,即onlayer特性
# what 代替图像的可视组件,相当于show表达式语句,此时name用于关联标签,举例而言,下面三个等价
# show expression w as a
# $ renpy.show("a", what=w)
# $ renpy.show("y", what=w, tag="a") # 此时忽略name
# zorder 相当于zorder特性
# tag 图像的标签,相当于as特性
# behind 表示在哪些图片的后面,相当于behind特性
renpy.hide(name, layer=None)
# 等价于hide语句
# name 要隐藏的图像名称
# layer 图像所在的图层名,若为None,则使用tag关联的默认图层
renpy.scene(layer='master')
# scene语句等价于清空图层后再调用一个show
# layer 要清空的图层名
于是,我们可以用函数定义transform(含参数的变换可以用偏函数),然后在show语句中传给at_list参数,之后运行完毕后再统一hide。

这里共有10行“Spell Card Attack!!”,明显是仿照ZUN先生在符卡攻击里的背景文字,用循环设定了每一个文字的位置和移动方向。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
image HLD2spellcardattack:
"item/eff_line.png"
crop(96, 0, 16, 128)
zoom 4.0
xanchor 0.5
yanchor 0.5
transform spellcardattack_move(x, y, direction):
alpha 0.0
rotate 45
xpos x
ypos y
xoffset -500 * direction
yoffset 500 * direction
parallel:
linear 6.0 xoffset 500 * direction yoffset -500 * direction
parallel:
linear 0.5 alpha 0.8
3.0
linear 0.5 alpha 0.0
python:
for i in range(-4, 6):
for j in range(-5, 5):
renpy.show("spellcardattack",
tag="attack"+str(i)+"i"+str(j),
at_list=[spellcardattack_move(1536+362*j, 540-144*i-362*j, i%2*2-1)],
behind=["魅须丸"])
如果你要控制的图片贴图是相同的,可以考虑SpriteManager。其性能更好,但只能处理固定的图片,只能修改他们的xoffset和yoffset字段。不过本人才疏学浅,这里就只用一个简单粗暴的例子来抛砖引玉了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
init python:
import math
def omg_update(st):
for i, it in enumerate(omg2s):
nst = st - 2
if st < 2:
r = 20 * 12 * st
else:
r = 20 * 12 * ( 2 + math.sin(nst))
rad = (i + nst) / 12 * math.pi * 2
rad = - rad
it.x, it.y = 960 + r * math.cos(rad), 540 + r * math.sin(rad)
return
def omg_event(ev, x, y, st):
pass
image omg_blue:
"item/bullet6.png"
crop(64,32,64,64)
parallel:
blur 5.0
ease 1 blur 0.0
parallel:
rotate 0
linear 2.0 rotate 360
repeat
python:
omg = SpriteManager(update=omg_update, event=omg_event)
omgs = [ ]
for i in range(18):
omgs.append(omg.create("omg_blue"))
del i
show expression omg as omg
SpriteManager的update参数,是每次要渲染时调用的函数,参数st是自显示开始的时间。我们用一个列表来存储所有的Sprite,然后遍历列表,对每一个Sprite操作。
事件和on
假设屏幕上有三位角色,常做的一件事是高亮正在说话的一位,或者着重强调刚刚变了表情的角色。这种小细节不会特意地给角色镜头,但是却能增加不少沉浸感。
并且,这些行动可以很好地用一个transform就写好。对于角色出现、隐藏、替换、被替换,都可以单独设定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
transform left(x=0.3, z=1.0):
yanchor 0.6
on show:
ypos 0.8
zoom z*0.95 alpha 0.0
xcenter x yoffset -20
easein .25 yoffset 0 zoom z*1.0 alpha 1.0
on hide:
zoom z*1.0 alpha 1.0
easeout .25 yoffset -20 zoom z*0.95 alpha 0.0
on replace:
zoom z*1.0 alpha 1.0
yoffset -20
easeout .1 yoffset 0
on replaced:
pass
show chimata 平视 at left
""
show chimata 惊讶 at left
""
show chimata 平视 at left
""
hide chimata at left
""
将使用到的角色的图片大小归整,定义好预先的位置和缩放,提供聚焦和失焦的动画,这样在角色进行一般的对话时,能帮助我们节省很多时间。
可视组件
在可视组件上作用变换
现在我们知道,定义image时可以使用ATL,也可以包含transform;transform由若干ATL定义,也可以包含图片;show的时候可以用at接transform,也可以用冒号接transform、ATL或图片。听着有些复杂,我们捋一捋。
能够显示在屏幕上的东西,都是可视组件(displayable),可视组件的名称(name)也就是我们在脚本中使用的图片的标签(tag),图片是最常见的可视组件。
将可视组件显示在屏幕上需要变换(transform),变换里有若干操作,譬如调节可视组件的位置、旋转、拉伸、透明度等等,可视组件经过变换后显示在屏幕上。变换是对可视组件的调整,因此如果出现两条对同一特性的修改,后作用的会覆盖前作用的。
此外,可视组件在变换后的结果可以定义为新的可视组件,就像图片经过PS后可以保存为新的图片。新的可视组件就可以继续再施加变换,仿佛有一种叠加的效果。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
transform t1:
zoom 2.0
xycenter (0.2, 0.5)
alpha 0.5
rotate 45
transform_anchor True
transform t2:
zoom 1.5
xalign 0.8
alpha 0.5
rotate 90
transform_anchor True
image chimata = At("千亦 笑", t1)
show 千亦 笑 as c1
show 千亦 笑 as c2 at t1
show 千亦 笑 at t1
show 千亦 at t2
show chimata at t2
下面的show一共五行,屏幕最下方的千亦是c1,它在默认位置上。c2在左边,它被应用了t1,也就是放大两倍,旋转45度,透明度减半。第三行的千亦首先应用了t1,接着又在第四行应用了t2,t2的属性会覆盖t1,因此是右侧较小的那个千亦——缩放1.5倍,透明度0.5,旋转90度。image语句定义了chimata这张图片,它是由“千亦 笑”这张图片应用t1变换得到后保存为chimata的,在那之后它再次应用了t2变换,那么它和第四行定义的千亦在视觉效果上就不一样了。它是chimata这张图片的缩放1.5倍,透明度0.5,旋转90度,和一开始的“千亦 笑”相比,已经是缩放3倍,旋转135度,透明度25了。
我们总结一下:可视组件是图片的类似物,ATL语句是对可视组件的操作,变换是若干ATL语句的集合。image语句可以将经过变换的可视组件定义为新的可视组件,可以通过At()或冒号来给出这一个或多个变换。
还有其他方式可以定义可视组件,例如contains语句,其可以把一个变换变为一个可视组件。在image的定义里,如果不用contains的话,会一直执行t1的repeat,因此i1的定义里第三行和第四行就永远也执行不到了。
1
2
3
4
5
6
7
8
9
10
11
12
13
transform t1:
"item/注意点 1.png"
0.25
"item/注意点 2.png"
0.25
repeat
image i1:
ycenter 0.5
contains t1
xalign 0.0
linear 5 xalign 1.0
show i1:
zoom 2
最后我们补充一下,当at后有不止一个transform时(也就是变换列表at_list),它们的作用和替换是怎样的吧。我们先引文档的描述。
某个ATL变换、内建变换或使用 Transform 定义的变换对象被同类变换替换时, 同名特性的值会从前一个变换继承到新的变换。不同类型的变换无法继承。 如果 show语句 中的at关键字后列出了多个变换待替换,则新变换列表从后往前依次替换,直到新替换变换列表全部换完。例如: e 变换替换了 c, d 变换替换了 b,而没有变换会替换 a。
1
2
3
show eileen happy at a, b, c
"我们稍等一下。"
show eileen happy at d, e
这是什么意思呢?至少我在读到这段话的时候是完全蒙头转向的。在搞懂之后回头来看,确实能发现他说的有道理,只是有道理得太迟了——我是自己琢磨出来的。
为方便大家理解,我们先明确,一个ATL语句相当于修改某一个特性,一个变换相当于多条打包的ATL语句,且这些语句修改的特性是不同的。如果有多条同名语句,后出现的会覆盖新出现的。 为了我表述方便,我们定义变换的拼合,如果后一个变换的ATL语句和前一个变换的ATL语句同名,那么后一个变换的ATL语句会覆盖前一个变换的ATL语句,否则只是合并。举例来说:
1
2
3
4
5
6
7
8
9
10
11
12
13
transform t1:
rotate 30
zoom 2.0
transform t2:
alpha 0.5
rotate 20
transform t1_cohere_t2:
t1
t2
transform t3:
rotate 20
alpha 0.5
zoom 2.0
这里,t1和t2的拼合和t3是一样的。后出现的rotate 20覆盖掉了rotate 30。我们姑且记作t1+t2=t3吧。
其次,冒号定义的变换,相当于直接在at最末尾加一些变换,也就是下面两个show效果是一样的:
1
2
3
4
5
6
7
8
transform t4:
matrixcolor BrightnessMatrix(0.5)
rotate 30
show img at t1, t4
show img at t1:
matrixcolor BrightnessMatrix(0.5)
rotate 30
最后,在show末尾的若干变换会从左到右复合起来。这里的复合就是做完一个再做第二个,因此不会出现ATL语句的覆盖,我们姑且记作t1×t2=t5吧,以下两个show效果是一样的。(如果图片不以(0.5, 0.5)作为anchor的话,可能会有平移,但是角度是没错的)
1
2
3
4
5
6
7
8
9
transform r1:
rotate 30
transform r2:
rotate 20
transform r1_comp_r2:
rotate 50
show img at r1, r2
show img at r1_comp_r2
那么我们现在表述一下变换列表的替换规律吧。如果替换后有若干变换,那么就从替换前的列表末尾取同样数量个变换,然后一一对应做拼合,成为本次show语句的变换列表。
还是以文档中给的例子为例,如果是a, b, c用d, e去替换,得到的就是b+d, c+e。有时这会给出一些反直觉的结果来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
transform t1:
zoom 2.0
xcenter 0.5
rotate 45
alpha 0.5
show 千亦 笑 at t1:
xcenter 0.8
zoom 2.0
rotate 45
alpha 0.5
"原图像的四倍 位置在0.8 旋转90度 透明度0.25"
show 千亦 帅气:
zoom 2.0
rotate 45
alpha 0.5
"原图像的两倍 位置在0.8 旋转45度 透明度0.5"
第一个show中,t1和show的冒号后定义的两个zoom会相乘,最终的放大倍数是4倍。之后,当我们在第二个show中重新指定了zoom特性,它只有一个变换,因此t1会被丢弃,放大倍数会重新回到2倍。 如果这样写的话,前后就不会有变化了(位置得重新写一遍,也有点难理解):
1
2
3
4
5
6
transform nothing:
xcenter 0.8
show 千亦 帅气 at nothing:
zoom 2.0
rotate 45
alpha 0.5
这是笔者走过的弯路——在任何编程语言中,都不要写出让人类难读而感到疑惑的代码。这里干干净净地把transform拆分开比较好。觉得复杂的时候就该定义新的可视组件了。
序列帧、Spine、Live2D
非想天则的素材里,人物的运动大概是连环画,这正巧可以给我们拿来做动图了。

1
2
3
4
5
6
7
8
init python:
def reimu_walkback_func(st, at):
dist = int(st * 24) % 8
dist = str(dist).zfill(3)
return "item/reimu/walkBack%s .png" % dist, 0.01
image reimu_walkback:
DynamicDisplayable(reimu_walkback_func)
用DynamicDisplayable可以把一个函数变为一个可视组件,这个函数返回一个Displayable对象,以及一个浮点数,表示再次调用该函数的时间,为空值则不再调用,直到玩家的下次互动。每次互动后,这个函数都会被调用。其他可视组件可以去文档找找看。
一些游戏用Spine来做2D骨骼动画,大体就是把人物拆分成若干部分,然后通过调整这些部分的位置、角度、缩放等属性来达到动画效果。这样就比连环画要自由得多。
我没在文档里找到Spine的相关内容,但是我们可以用个笨办法——把Spine转成序列帧动画,这样的在线工具也是有的,不过唯一缺陷可能就是占存储空间有些大了吧。
说到Spine就顺带提一句Ren’Py支持的Live2D,在启动器的设置 > 安装库里可以看到使用Live2D需要的Cubism SDK。根据指引放置在Ren’Py的SDK目录下,点击安装就可以使用Live2D了。
笔者倒是完全不懂Live2D,大概看看里面会有什么文件。
- cmo3 模型文件
- can3 基本动画文件
- moc3 模型数据
- exp3.json 表情数据
- motion3.json 动作数据
- model3.json 模型设定文件
- physics3.json 物理模拟设定文件
- pose3.json 姿势设定文件
- cdi3.json 辅助显示的文件
可以看到哪些以motion3.json结尾的就是可以使用的动作了,然后exp3.json结尾的就是表情。这些文件名全转小写,然后如果和model3.json的模型名相同的话,就删去这个模型名。例如如果模型名是“mao”,那么用“mtn01”这个动作名来调时,动作文件可以命名为“mao_mtn01.motion3.json”或“mtn01.motion3.json”。
来试一下:
1
2
3
4
5
define config.gl2 = True # 启用OpenGL 2.0渲染器
image hiyori = Live2D("Resources/hiyori_pro_zh/runtime/hiyori.model3.json", base=0.9, loop=True)
show hiyori m01

如果有多个动作的话,动作会按顺序执行,如果开启循环的话就会在执行完最后一个动作后循环它。如果有非排他性的表情,那么就会保持这个表情,除非显式地移除。
1
2
3
4
5
6
image mao = Live2D("Resources/mao_pro_zh/runtime/mao_pro.model3.json", base=0.9, loop=True)
show mao special_01 mtn_01
"show mao special_01 mtn_01"
show mao exp_02
"show mao exp_02"

我对此也了解不深,此处就简单带过吧。
类图像的可视组件
图片是一种最简单的可视组件,除此之外我们也有别的需求,比如图片的组合。这些“类图像”(imagelike)的可视组件类定义在renpy/display/imagelike.py下。像图像一样,它们有着自己的位置、尺寸等属性。
这种图片的组合可以被应用在立绘的拼接上,角色的立绘往往有着一套相似的样式并在细微之处有微小的差别。比如全身的动作都是一模一样的,只是把微笑改成哭脸或者其他表情。又或者右半身保持不变,只是举起左手竖大拇指等等。这样的一组图片一般称为一套差分。我们固然可以为每个差分都单独绘制一套立绘,但在游戏开始后再拼接好处也很多,比如差分要组合的东西很多——譬如三套衣服八套表情两套特效的时候,又或者眼睛五套嘴巴五套的时候,把每一张立绘都排列组合单独保存成文件会占用不少空间——毕竟这只是个小游戏,占用那么多磁盘空间是要做什么?(不过dairi老师的差分已经是拼接好的了)

我们再把立绘拆出来,png是无损压缩格式,表情的差分只需要几个KB。接下来在游戏里拼接它们,以下是几个示例:
1
2
3
4
5
6
7
8
9
10
11
12
image 天弓千亦 微笑 = Composite(
(1084, 1220),
(0, 0), "images/dairiComp/Dairi天弓千亦 身体.png",
(0, 0), "images/dairiComp/Dairi天弓千亦 微笑.png",
)
image 天弓千亦 微笑 尾气 = Composite(
(1084, 1220),
(0, 0), "images/dairiComp/Dairi天弓千亦 身体.png",
(0, 0), "images/dairiComp/Dairi天弓千亦 微笑.png",
(0, 0), "images/dairiComp/Dairi天弓千亦 尾气.png",
)
这里第一个元组是图片的尺寸,之后的元组和图片名则是图片的位置和图片名。组合好后,便可以像一般的图片一样使用了。
renpy还提供了一种叫做层叠式图像的方法来组合图片。优点是图像的属性也会自动生成,而不需要我们把每种情况都单独写一个image语句。
Crop是裁剪,第一个元组是裁剪的左上角坐标,以及裁剪的宽和高。
1
image 千亦头像 微笑 = Crop((240, 40, 360, 360), "天弓千亦 微笑")
想要一张纯色的图片:
1
2
3
4
image bluegreen = Solid("#39c5bb")
show bluegreen:
pos (0.25, 0.25)
xysize (0.5, 0.5)
Frame是所谓的九宫格切图,一般用于UI界面,比如窗口、按钮、聊天气泡这种希望可以随意伸缩的组件。示意图如下:
![]()
在Renpy中的定义为:
1
Frame(image, left=0, top=0, right=None, bottom=None, tile=False, **properties)
其中image是图片,left和top是左边界尺寸和上边界尺寸,right和bottom是右边界尺寸和下边界尺寸,为空时分别和左上相等,tile决定中间的部分是平铺还是拉伸。
有时会有这样的需求吧:登场人物是一个神秘角色——说是神秘角色但是大家心中都有些许猜测,但是直接把立绘放出来又太直白了,我们想要加一层黑色的阴影,而且最好是上半身纯黑,只露出一点下半身的亮色,就像这样。

1
2
3
4
5
6
7
8
show 天弓千亦 微笑 黑:
zoom 1.25
anchor (0.4, 0.32)
pos (0.2, 0.45)
cmt "“副职业是侦探~”\n我记得你曾经这样自称过,怎么事到如今却问出了这样没品的问题?" (name = "")
r "我有说错什么吗?{p}天弓千亦小姐。"
show 天弓千亦 帅气 尾气 subete with dissolve
cmt "忘记了吗?我这段时间投资的项目,就是“集换式卡牌游戏”。\n这个交易系统本来就是以我的力量为基础设计的,我本人想绕过它还不是轻而易举!"
为此,我们需要一张上黑下透明的渐变图。

而后使用AlphaMask(child, mask, **properties),这种可视组件使用child作为底图,但它的透明通道要乘以mask。换句话说,经过AlphaMask后,我们的渐变图变成了一张保持大小,但是裁剪出了千亦的轮廓的图片。再把这张图片叠放在千亦的立绘上,就得到了我们想要的效果。
1
2
3
4
5
6
7
8
9
10
11
12
transform chimata_size:
xysize (1084, 1220)
image 天弓千亦 黑 = AlphaMask(
At("gradient_mask_character", chimata_size),
"天弓千亦 微笑"
)
image 天弓千亦 微笑 黑:
chimata_size
contains:
"天弓千亦 微笑"
contains:
"天弓千亦 黑"
图像处理器
顾名思义,处理图像的。这里的很多类定义在renpy/display/im.py下。
im.AlphaMask(base, mask, **properties),使用base作为图像的RGB数据,mask的红色通道作为透明通道。注意和类图像的可视组件使用起来并不相同。 im.Crop(im, rect),裁剪图像,rect是裁剪的左上角坐标和宽高四元组。 im.Composite(size, *args, **properties)和Composite用法一致,依次输入尺寸和若干要组合的图像处理器。 im.Scale(im, width, height, bilinear=True, **properties),缩放图像到指定尺寸。bilinear表示使用双线性插值算法,否则使用最近邻。 im.FactorScale(im, width, height=None, bilinear=True, **properties),和im.Scale类似,但默认保持宽高比。 im.Flip(im, horizontal=False, vertical=False, **properties),水平或垂直翻转图像。 im.Rotozoom(im, angle, zoom, **properties),旋转并缩放图像,逆时针为正,角度值。 im.Tile(im, size=None, **properties),平铺图像,size是平铺的尺寸,宽高的元组,为空则为屏幕宽度到屏幕高度。 im.Image(filename, **properties),要加载的文件名 im.Data(data, filename, **properties),以二进制数据关联图像名
Matrixcolor
我们在介绍变换特性的时候跳过了matrixcolor,现在来细细说一下和图片颜色有关的东西。
众所周知,现代的图片格式通常存储RGBA四个值,也叫四个通道。其中RGB是三原色,A表示不透明度(当你意识到朋友给你传来的透明图片其实只是一张灰白格子背景的的jpg)。这些值在进入Ren’Py后,存储的值范围是0.0-1.0,alpha通道是越高越“不透明”,但由于汉语的习惯,我想强调这一点时会说“不透明度”,当提到“透明度”时,还是越高越透明。
下面我们介绍颜色是如何混合的,将有前景色和背景色:
\[c_f=(r_f,g_f,b_f,a_f), c_b=(r_b,g_b,b_b,a_b)\]混合后得到:
\[c=(r,g,b,a)=c_f*c_b\]其中举红以赅蓝绿:
\[r=\frac{r_f \cdot a_f + r_b \cdot a_b \cdot (1-a_f)}{a_f + a_b \cdot (1-a_f)}\] \[a=a_f+a_b(1-a_f)\]很好理解,颜色其实是加透明度的权来平均,前景色透明多少,就会透过来相应比例的后景色,而前景色本身则会失掉相应的颜色。也就是说,在计算中,我们真正看到的颜色,往往是图片本身的颜色与自身不透明度相乘后的结果。也就是$r’=ra$。这个过程叫做预乘,Ren’Py中存储的图片颜色都是经过预乘的,这样他们在计算颜色混合时可以直接:
\[r'=r_f'+r_b'(1-a_f')\] \[a'=a_f'+a_b'(1-a_f')\]
我们来试着计算一下,上图是一张纯色红矩形,透明度50%,分别叠在纯黑和纯白的不透明背景上的图片。
因而红色的颜色向量为$(1,0,0,0.5)$,经过alpha预乘后是$(0.5,0,0,0.5)$,黑色的颜色向量为$(0,0,0,1)$,白色的颜色向量为$(1,1,1,1)$。
叠在黑色背景上是:
\[(0.5,0,0,0.5) * (0,0,0,1) = (0.5,0,0,1)\]叠在白色背景上是:
\[(0.5,0,0,0.5) * (1,1,1,1) = (1,0.5,0.5,1)\]所以左边的颜色看起来比纯红色要更暗一些,右边的看起来更亮一些,读者可以用一些取色工具来验证一下。两者都不透明,因为叠在了不透明的背景上,不可能再有透明度了。
如果说颜色是一个四维向量,那么可以用一个4*4的矩阵来表示对颜色的线性变换。我们可以使用transform中的matrixcolor。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
show 千亦 笑 at truecenter:
zoom 2.0
show 千亦 笑 at truecenter as cmt2:
zoom 2.0
xoffset -500
matrixcolor Matrix([ 0.0, 1.0, 0.0, 0.0,
1.0, 0.0, 0.0, 0.0,
0.0, 0.0, 1.0, 0.0,
0.0, 0.0, 0.0, 1.0, ])
show 千亦 笑 at truecenter as cmt3:
zoom 2.0
xoffset 500
matrixcolor Matrix([ 0.299, 0.587, 0.114, 0.0,
0.299, 0.587, 0.114, 0.0,
0.299, 0.587, 0.114, 0.0,
0.0, 0.0, 0.0, 1.0, ])

左边的图交换了红色和绿色(观察一下彩虹色的发箍),右边的图则是我们熟悉的灰度图,灰度的计算公式是一个经验公式,是一种常用的比较符合人类色彩认知的系数:
\[gray = 0.299 \cdot r + 0.587 \cdot g + 0.114 \cdot b\]曾经有一个哲学悖论,大致是说如果一个人的视觉上会将所有红色看成绿色,所有绿色看成红色(也就是在他眼里千亦是左边那张图的样子),然而因为他从小就和大家一起学习,把他眼中的绿色叫作红色,把他眼中的红色叫做绿色,所以从他的话语中完全无法觉察出他的色彩感知有问题。那么他要如何知道自己与众不同呢?抛开哲学的内容,这个假设其实就比较难做到,因为红色和绿色天然就有差别,人们会觉得绿色更明亮一些,而红色更暗一些。我们可以让它去测一下他眼中的灰度对三原色的系数,如果他觉得绿色更暗,我们就知道他眼中的颜色是反的;如果他觉得两个没什么区别,那他可能是红绿色盲,如果他觉得红色更暗,那他眼中的颜色就是正常的。事实上每个人对色觉的感知都有一定偏差,上面的公式也有好多个版本。再者,会有人说他眼中的红和绿是我们从未感知过的红和绿,在他眼里红就是要更明亮,从而得出和正常人一致的灰度系数来。那么这个问题其实就和颜色对换没什么关系了,单纯变成了我眼中的颜色可能和你眼中的颜色有差异罢了,毋庸提及颜色对换的种种。我只是为了说明用颜色对换在这个哲学问题里体现主观质感,在科学上有一定瑕疵罢了,色彩悖论的哲学内核是一种无法检验的,“意识是否有独立于物质的‘多余’的东西”的讨论,不过那就和我们这篇文章跑题太远了。

这是归言录中的白玉楼的背景,容我们拿来一用,作如下变换:
1
2
3
4
5
6
show bg 白玉楼 98145894:
fit "cover"
matrixcolor Matrix([0.247, 0, 0, 0,
0, 0.333, 0, 0,
0, 0, 0.721, 0,
0, 0, 0, 1])

竟然变成了夜晚的样子,可以看到调暗的同时,蓝色保留了大部,显得色调以蓝色为主。据说人眼在暗时对蓝色会更敏感,这个效应叫浦肯野效应。
类似地,如果想画出“血月”或者黄昏的气氛,也可以相应地调节系数,再给一例:
1
2
3
4
5
6
show bg 白玉楼 98145894:
fit "cover"
matrixcolor Matrix([1, 0, 0, 0,
0, 0.922, 0, 0,
0, 0, 0.231, 0,
0, 0, 0, 1])

但是,Matrix类并未提供插值,也就是说你没法写出linear 5 matrixcolor Matrix(...)的动画来,一般而言,你需要这样一个类,其实现一个函数,传入一个0.0-1.0的值,返回一个Matrix对象。例如如下的TintMatrix类,它的__call__方法传入旧值和新值的线性插值比例,返回一个Matrix对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
class TintMatrix(ColorMatrix, DictEquality):
"""
:doc: colormatrix
A ColorMatrix can be used with :tpref:`matrixcolor` to tint
an image, while leaving the alpha channel alone.
`color`
The color that the matrix will tint things to. This is passed
to :func:`Color`, and so may be anything that Color supports
as its first argument.
"""
def __init__(self, color):
self.color = Color(color)
def __call__(self, other, done):
if type(other) is not type(self):
# When not using an old color, we can take
# r, g, b, and a from self.color.
r, g, b, a = self.color.rgba
else:
# Otherwise, we have to extract from self.color
# and other.color, and interpolate the results.
oldr, oldg, oldb, olda = other.color.rgba
r, g, b, a = self.color.rgba
r = oldr + (r - oldr) * done
g = oldg + (g - oldg) * done
b = oldb + (b - oldb) * done
a = olda + (a - olda) * done
# Update the tint with opacity from the alpha channel.
r = 1 - (1 - r) * a
g = 1 - (1 - g) * a
b = 1 - (1 - b) * a
# Return a Matrix.
return Matrix([ r, 0, 0, 0,
0, g, 0, 0,
0, 0, b, 0,
0, 0, 0, 1 ])
这里看一下其父类ColorMatrix类的定义,它默认根据一个值来调用自己的get方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class _BaseMatrix(object):
"""
:undocumented:
Documented in text. The base class for various *Matrix classes
that are intended to return a Matrix, both ColorMatrix and
TransformMatrix.
"""
def __init__(self, value=1.0):
self.value = value
def __call__(self, other, done):
if type(other) is not type(self):
return self.get(self.value)
value = other.value + (self.value - other.value) * done
return self.get(value)
def __mul__(self, other):
return _MultiplyMatrix(self, other)
class ColorMatrix(_BaseMatrix):
"""
:undocumented:
Documented in text. The base class for various *Matrix classes
that are intended to return a Matrix that transforms colors.
"""
pass
于是我们可以看到很多预定义的ColorMatrix派生类,譬如调节亮度的BrightnessMatrix,value的取值范围是-1到1;又或者反转颜色,取值范围是0到1。用这些就可以做出电闪雷鸣、或者是恐怖片里的反色效果了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class BrightnessMatrix(ColorMatrix, DictEquality):
"""
:doc: colormatrix
A ColorMatrix that can be used with :tpref:`matrixcolor` to change
the brightness of an image, while leaving the Alpha channel
alone.
`value`
The amount of change in image brightness. This should be
a number between -1 and 1, with -1 the darkest possible
image and 1 the brightest.
"""
def get(self, value):
return Matrix([ 1, 0, 0, value,
0, 1, 0, value,
0, 0, 1, value,
0, 0, 0, 1 ])
class InvertMatrix(ColorMatrix, DictEquality):
"""
:doc: colormatrix
A ColorMatrix that can be used with :tpref:`matrixcolor` to invert
each of the color channels. The alpha channel is left alone.
`value`
The amount to inverty by. 0.0 is not inverted, 1.0 is fully
inverted. Used to animate inversion.
"""
def get(self, value):
d = 1.0 - 2 * value
v = value
return Matrix([ d, 0, 0, v,
0, d, 0, v,
0, 0, d, v,
0, 0, 0, 1, ])
其他颜色矩阵请参阅文档,可以修改图片的亮度、对比度、饱和度、色调、透明度等等。
最后提及,不要忘记给颜色矩阵赋初值,也就是实践上要这么使用:
1
2
3
4
5
show bg 白玉楼 98145894:
fit "cover"
matrixcolor TintMatrix("#ffffff") * SaturationMatrix(1.0)
linear 2.0 matrixcolor TintMatrix("#ccccff") * SaturationMatrix(0.0)
linear 2.0 matrixcolor TintMatrix("#ffffff") * SaturationMatrix(1.0)
转场
一个场景的故事讲完了,如何过渡到下一个场景?具体的切换效果Ren’Py提供了许多,我喜欢的是最简单的溶解,简单,并且又给人回味。

1
2
3
4
scene bg 红魔馆森林 with dissolve:
zoom 2.0 yalign 1.0 xalign 0.5
ease 3.0 yalign 0.2 zoom 1.2
"怀抱着这样的想法,大百足开始了她的节食生活。\n这份决意究竟能坚持几个月……几周……几天?"
即使是简单的溶解,也有一种仰望晴天的感觉。
1
2
3
4
5
6
7
8
9
10
11
12
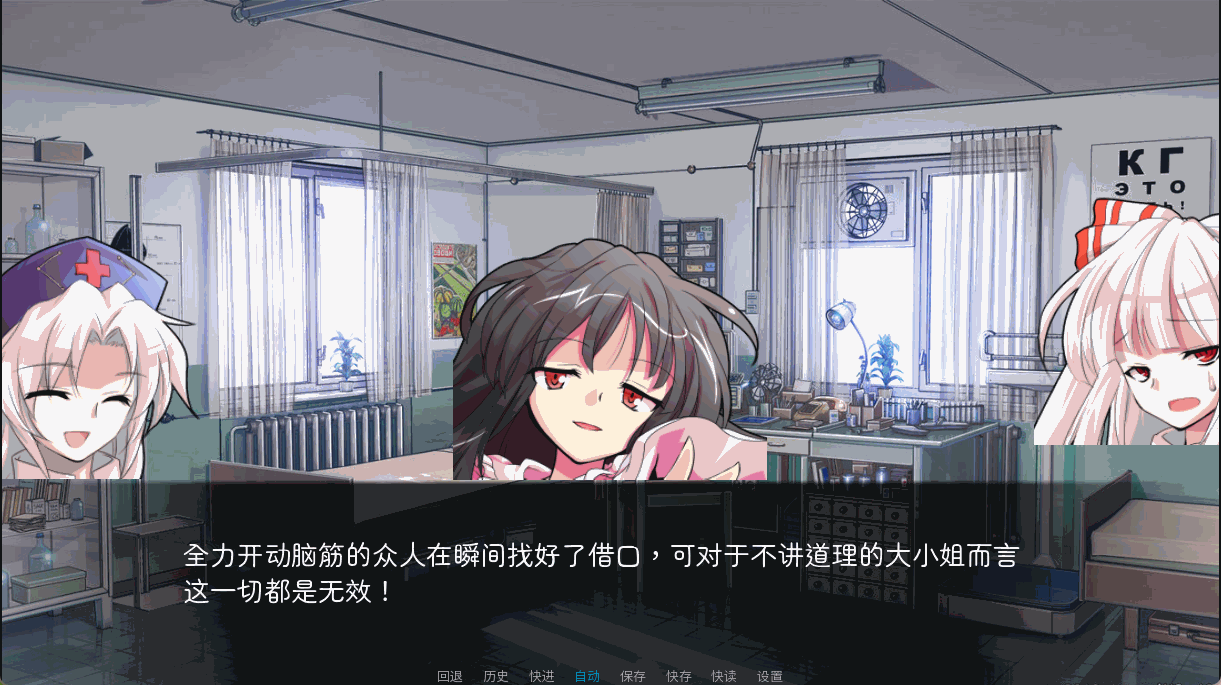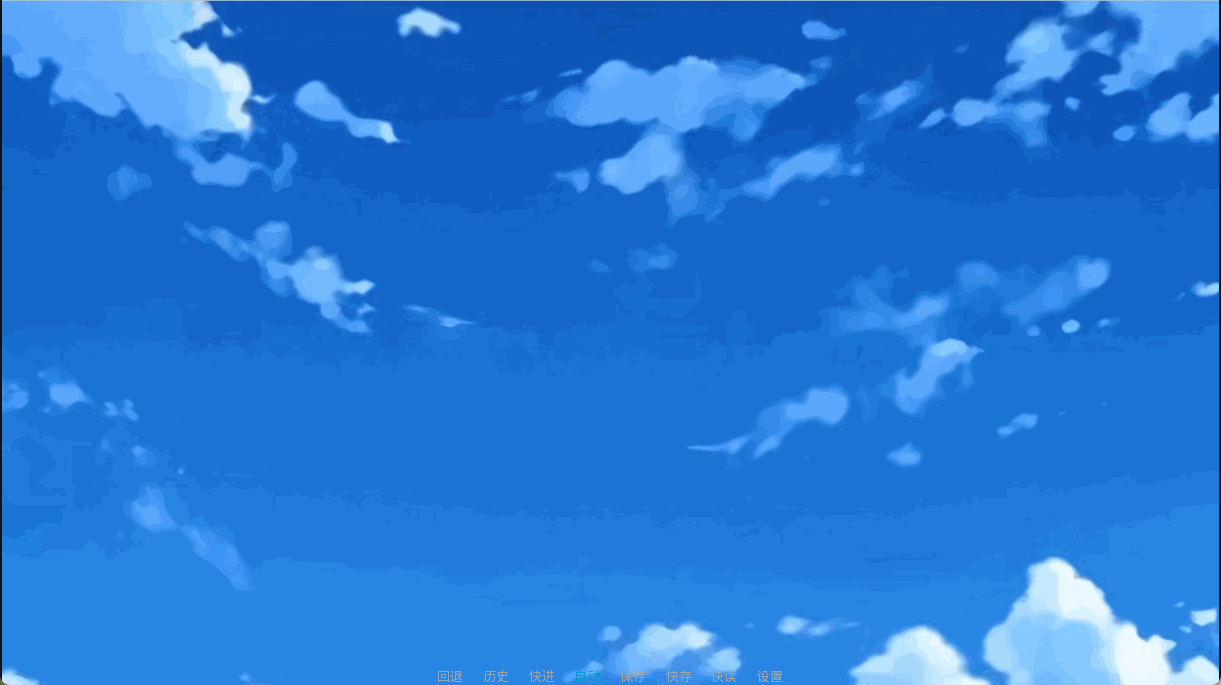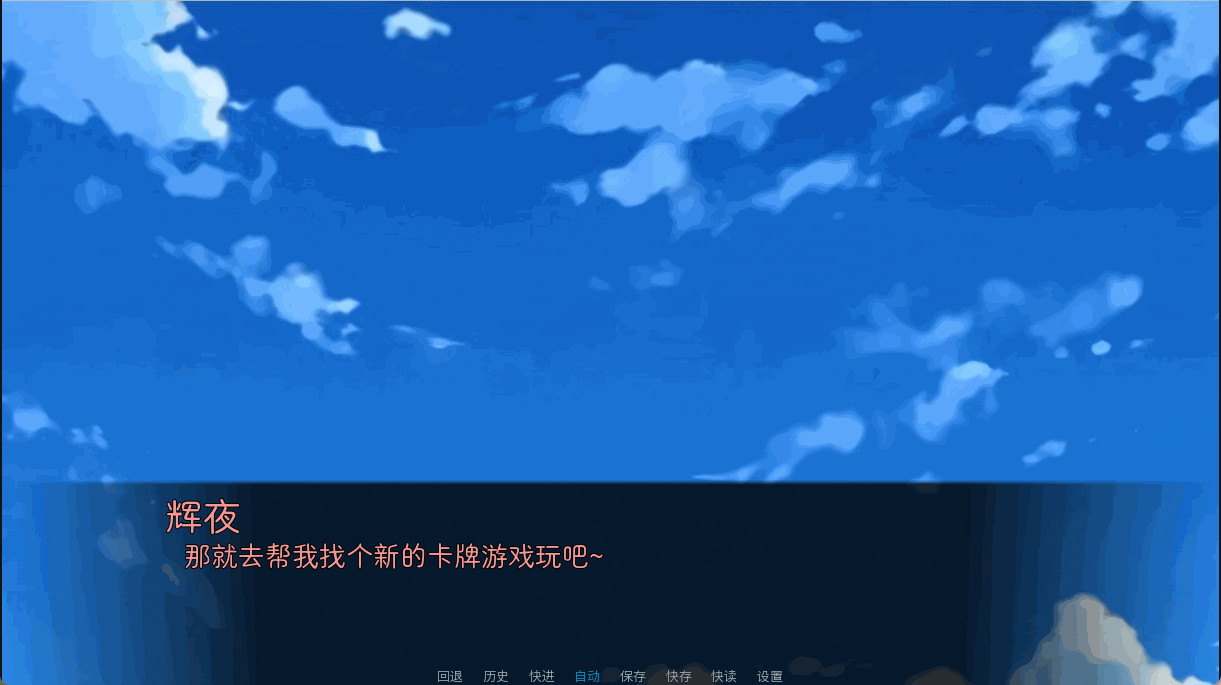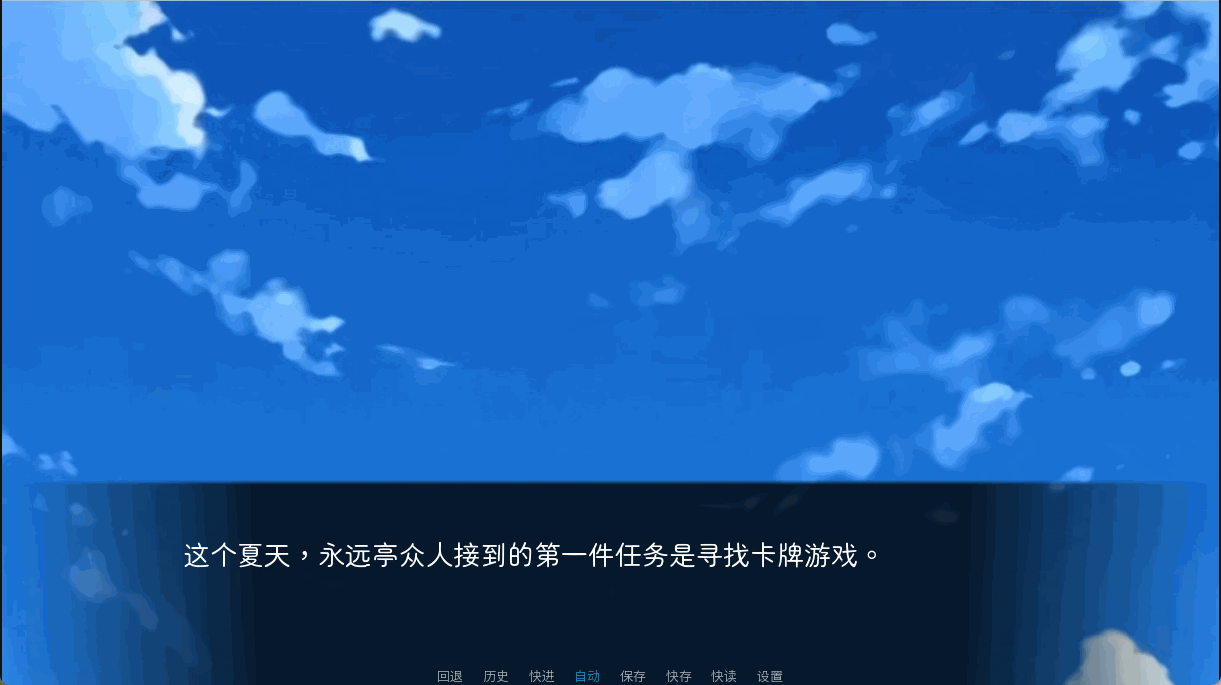
"全力开动脑筋的众人在瞬间找好了借口,可对于不讲道理的大小姐而言这一切都是无效!"
show 辉夜 笑 with dissolve
scene bg 天空 with Dissolve(2.0):
top
zoom 1.2
ease 10.0 zoom 1.4 yoffset 0.1
pause 1.0
k "那就去帮我找个新的卡牌游戏玩吧~"
"这个夏天,永远亭众人接到的第一件任务是寻找卡牌游戏。"
window hide
pause 3.0
stop music fadeout 2.0
with语句用于引导一个转场类,dissolve是Dissolve的一个实例,定义在renpy/common/00definitions.rpy中。
1
2
3
define fade = Fade(.5, 0, .5) # Fade to black and back.
define dissolve = Dissolve(0.5)
define pixellate = Pixellate(1.0, 5)
介绍参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
Fade(out_time, hold_time, in_time, *, color="#000")
# out_time 旧场景淡出时间
# hold_time 纯色的color持续时间
# in_time 新场景淡入时间
# color 淡出淡入的颜色,默认是黑色
Pixellate(time, steps)
# time 转场总时间
# 像素化的步数,例如5步想刷会创造出32*32的像素
Dissolve(time, *, alpha=False, time_warp=None, mipmap=None)
# 溶解的总时间
# alpha 无用
# time_warp 之前曾提到过的,给时间插值的缓动函数
# mipmap 当溶解缩放到图片原尺寸的一半以下时,可以设置为True来启用纹理映射
下面是溶解的升级版,我们可以用一张图片来控制溶解的过程。白色的像素先溶解,黑色的像素后溶解,不同深度的灰就代表了先后的顺序。如下图就是一张从左向右的溶解:

这个就稍显复杂了,最亮的是左上角,于是像一束光一样从左上角向右下角射出,而后其余部分是水彩的斑块,于是带着这种触感再从右下角向左边和上方扩散。

还是看一下真实的应用场景吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
image sepia_医务室:
"background/bg 医务室2.jpeg"
matrixcolor SepiaMatrix()
show sepia_医务室:
subpixel True
top
xoffset -80
zoom 1.7
linear 20.0 xoffset 80 zoom 1.5
show 八意永琳:
yanchor 0.0
zoom 2.6
xcenter 0.95
ypos 0.02
with cmet
show 月之头脑:
xalign 0.6
yalign 0.75
zoom 3.6
with ImageDissolve("transform/wipeleft.png", 1.1, ramplen=8)
"21世纪初期,知名生物学家八意永琳曾经这样说过:"

这里,with语句是会占用一定的时间的,从上到下依次执行。此外,with语句的作用范围是之前所有的show和hide等等,所以可以看到永琳的立绘和背景是一起溶解而出,而后才是“月之头脑”的名牌的。当然,如果不想沾上任何转场,可以用with None。
类的定义:
1
2
3
4
5
6
7
ImageDissolve(image, time, ramplen=8, *, reverse=False, time_warp=None, mipmap=None)
# image 控制图像,需要与场景尺寸一致
# time 转场总时间
# ramplen 控制溶解的步数,默认8步,必须为2的整数幂,当纯白色像素溶解后,剩余的像素会以ramplen为步长进行溶解。这个数字越小,溶解就越细腻,反之则越平滑
# reverse 是否反向溶解,也就是从黑色像素开始溶解
# time_warp 缓动函数
# mipmap 纹理映射
有了图像溶解,我们便可以做出各种奇妙的转场效果了,睁眼动画、交叉溶解、玻璃碎裂、网格、旋转、矩形向内、螺旋、波纹、涂鸦等等。如果熟悉的话也可以自己制作转场所使用的图片。
接下来是转场的组合:
1
2
MultipleTransition(args)
# args 一个列表,元素为奇数个,其中场景和转场交替出现,每一个转场都以它前一个元素的场景作为旧场景,后一个元素的场景作为新场景。可以用`False`表示整个MultipleTransition的旧场景,True表示新场景
使用例如下:
1
2
3
4
5
define wipeleft_transition = MultipleTransition([
False, ImageDissolve("transform/wipeleft.png", 0.5, ramplen=64),
Solid("#000"), Pause(0.25),
Solid("#000"), ImageDissolve("transform/wipeleft.png", 0.5, ramplen=64),
True])
这个转场表示从左向右擦除为黑色,然后再从左向右变为新场景,给人一种翻篇的感觉。

我特别喜欢馆长海皇使用的这种类型的转场,简洁而有动感,类似的转场还有许多:

并且,其在Ren’Py中的实现也相当简单:真正的背景不需要转场,只需要加一个缓慢的平移以减少单调,转场实际上作用在遮盖其的白色背景上,注意到转场其实发生了两次,第一次是纯白色转变为带有透明度的白,露出其后真正的背景,第二次是这白色彻底变透明,两次的转场使用的是同一个ImageDissolve的图片。

无论用何种方式画出这张图片,只要做两次ImageDissolve即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
show bg 三途川:
fit "cover"
xcenter 0.65
zoom 1.25
xoffset 50
linear 10 xoffset -50
show white
with None
pause 0.5
show white:
alpha 0.5
with ImageDissolve("transform/wipe_line.png", 0.8)
pause 0.5
show white:
alpha 0.0
with ImageDissolve("transform/wipe_line.png", 0.8)
我还想画一些更自由的转场,AI说Krita可以导出绘画过程:

那么稍微写一点代码就可以把这个做成一个转场了。
![]()
你可能注意到了,这种转场有一个问题,已经变成新场景的像素没法变回去,换句话说如果我们想做出这种转场,ImageDissolve就无能为力了。
不过,我们可以套用之前提到的AlphaMask的思路,来看:
1
2
3
4
5
AlphaDissolve(control, delay=0.0, *, reverse=False, mipmap=None)
# control 控制转场的transform
# delay 转场总时间
# reverse 反转黑白像素
# mipmap 纹理映射
AlphaDissolve可以把一个transform的alpha通道当做溶解的控制,其中纯黑代表旧场景,纯白代表新场景,灰度代表新旧场景混合的比例,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
transform circle_transition:
"transform/white_circle_blur.png"
xcenter -0.4
ycenter 0.5
zoom 1.0
easein 0.8 xcenter 1.0 zoom 1.2
easeout 0.8 zoom 8.0
show bg 三途川:
fit "cover"
xcenter 0.65
zoom 1.25
xoffset 50
linear 10 xoffset -50
show dark
with None
pause 1.0
show dark:
alpha 0.0
with AlphaDissolve(circle_transition, 1.6)
Ren’Py提供了一个叫做CropMove的转场,它是通过矩形裁剪和移动来实现转场的。具体而言就是,给定新场景的初始位置和初始裁剪,以及新场景的最终位置和最终裁剪,在这其中平滑过渡。例如如下的转场:

参数定义为:
1
2
3
4
5
6
7
8
# 相对于场景图片 裁剪的初始位置和尺寸
startcrop (x, y, width, height)
# 相对于游戏窗口 新场景的初始位置
startpos (x, y)
# 裁剪的最终位置和尺寸
endcrop (x, y, width, height)
# 新场景的最终位置
endpos (x, y)
初始时,新场景位于最右侧,也就是(1.0, 0.0),裁剪的内容是新场景图片最左侧的一条部分,也就是(0.0, 0.0, 0.0, 1.0);结束时,新场景移动到最左侧,也就是(0.0, 0.0),裁剪的内容现在是完整的新场景了,也就是(0.0, 0.0, 1.0, 1.0)。这个转场模式被叫做slideleft。

再来一例,新场景初始位置是(0.5, 0.5),末位置是(0.0, 0.0),一开始裁剪的是图片最中间,大小为0,也就是(0.5, 0.5, 0.0, 0.0),最后图片完全显示,也就是(0.0, 0.0, 1.0, 1.0),这个转场模式被叫做irisout。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
define wiperight = CropMove(1.0, "wiperight")
define wipeleft = CropMove(1.0, "wipeleft")
define wipeup = CropMove(1.0, "wipeup")
define wipedown = CropMove(1.0, "wipedown")
define slideright = CropMove(1.0, "slideright")
define slideleft = CropMove(1.0, "slideleft")
define slideup = CropMove(1.0, "slideup")
define slidedown = CropMove(1.0, "slidedown")
define slideawayright = CropMove(1.0, "slideawayright")
define slideawayleft = CropMove(1.0, "slideawayleft")
define slideawayup = CropMove(1.0, "slideawayup")
define slideawaydown = CropMove(1.0, "slideawaydown")
define irisout = CropMove(1.0, "irisout")
define irisin = CropMove(1.0, "irisin")
这是Ren’Py预定义的转场,可以直接使用,详细的参数可以在renpy/display/transition.py中查到。如果要自定义裁剪和移动,可以在CropMove中把模式设置为custom,CropMove类的声明如下:
1
2
3
4
5
6
7
classCropMove(time,
mode='slideright',
startcrop=(0.0, 0.0, 0.0, 1.0),
startpos=(0.0, 0.0),
endcrop=(0.0, 0.0, 1.0, 1.0),
endpos=(0.0, 0.0),
topnew=True) # 如果为False,被裁剪和移动的是旧场景
事实上这种简单的裁剪和移动,我们也可以用变换来仿制,比如这个开门的效果:

实际上是用两张图片向两边移动来实现的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
show bg 永远亭 apk behind bgt1:
fit "cover"
xalign 0.65
show bg 永远亭医务室 as bgt1:
crop(0, 0, 1024, 1024)
zoom 1.055
xanchor 1.0
xpos 0.5
ease 1.0 xoffset -1024
show bg 永远亭医务室 as bgt2:
crop(1024, 0, 1024, 1024)
zoom 1.055
xanchor 0.0
xpos 0.5
ease 1.0 xoffset 1024
什么?你想让它像门一样推开,看起来像3D一样?我还真不知道正经的实现方式是什么,放在之后再说吧。
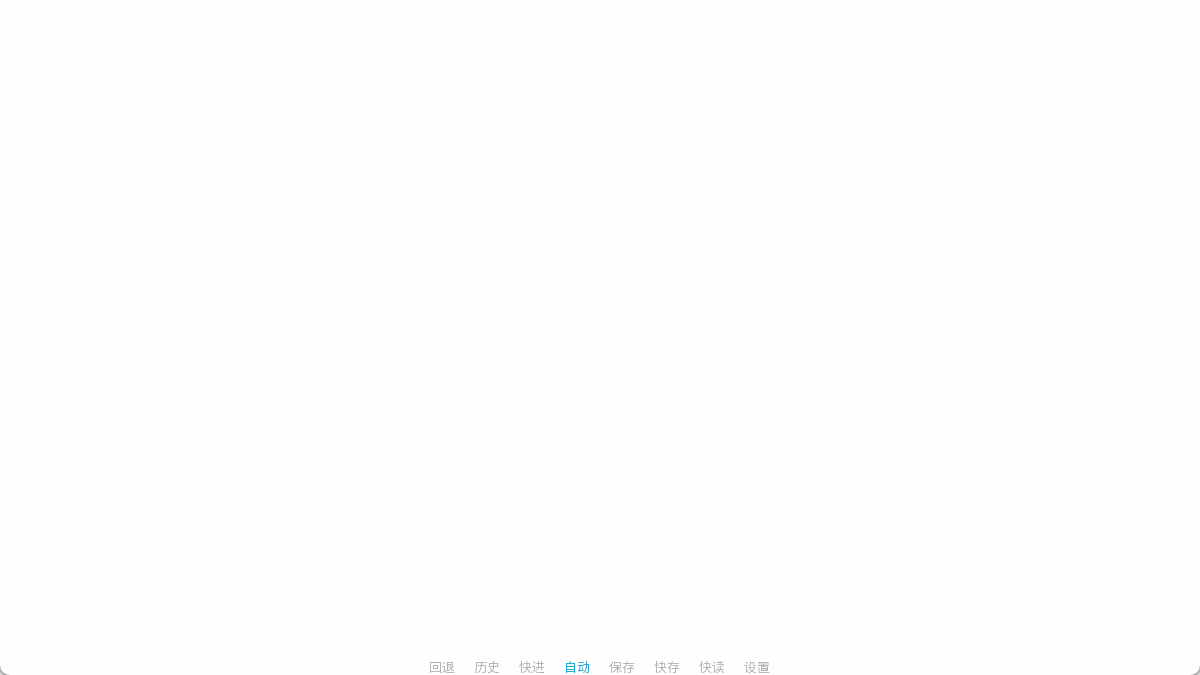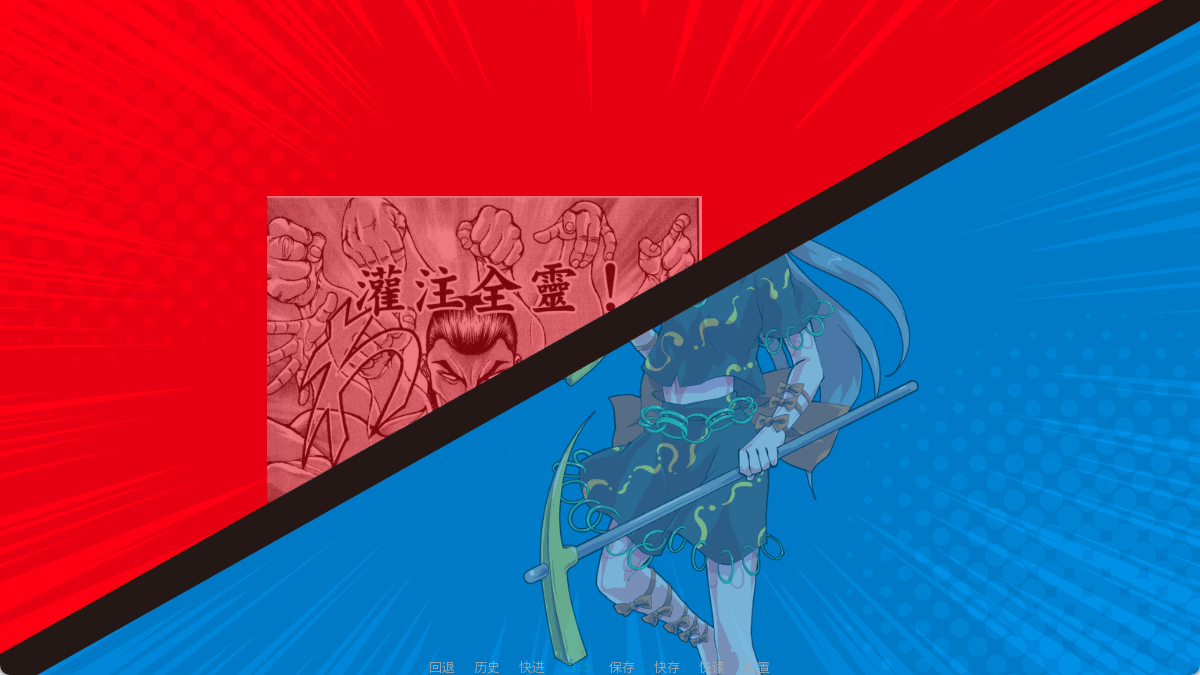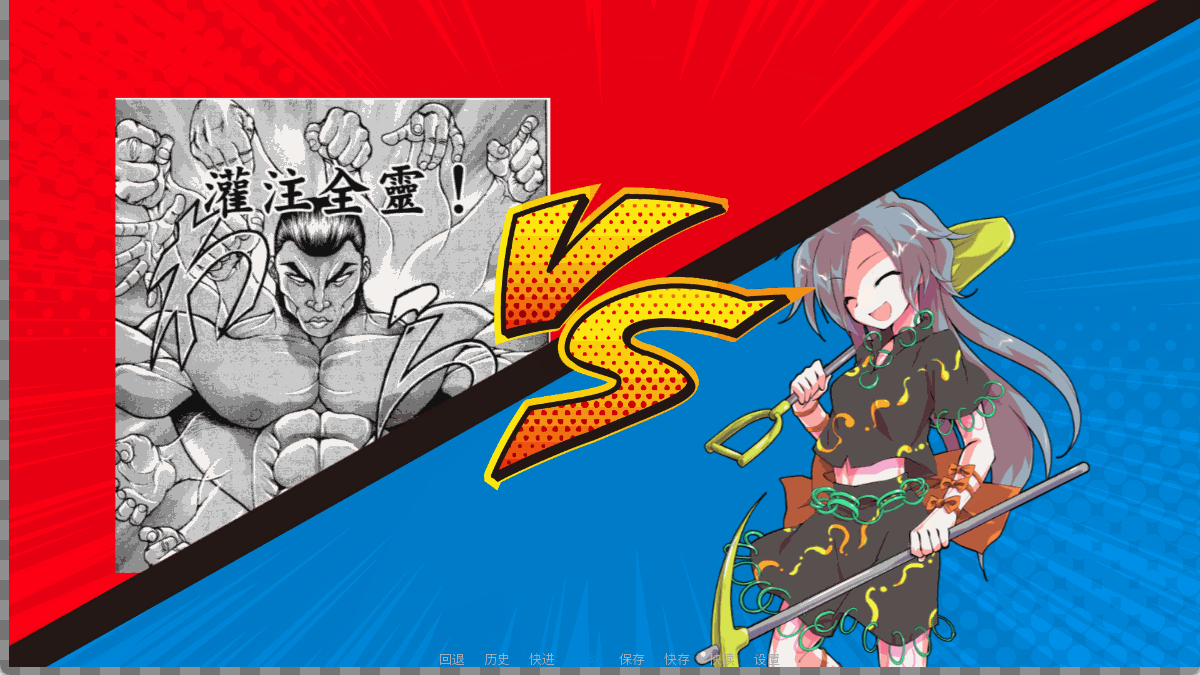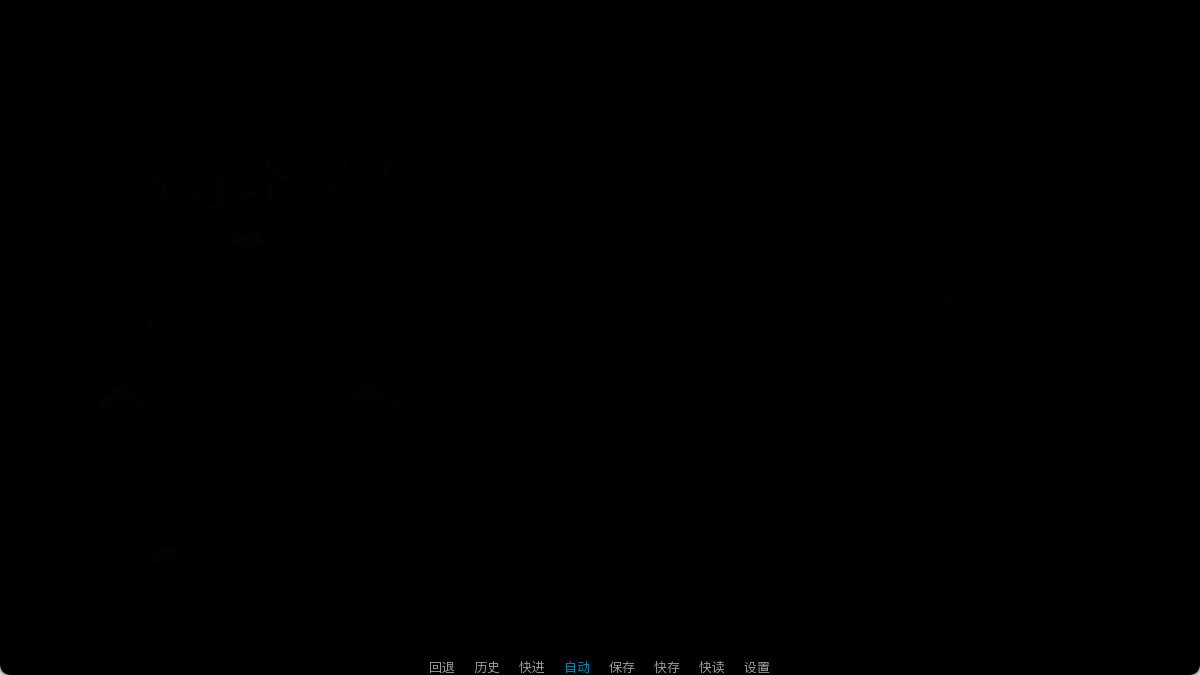
来看这个效果(为什么这个配色搞得像宝可梦对战一样)。
蓝色三角形遮挡住了烈,烈遮挡住了红色三角形,红色三角形遮挡住了百百世,百百世又遮挡住了蓝色三角形。所以如果只是把这四张图片放在一起的话,遮挡关系是没法实现的。不过也很简单,用AlphaMask把左上角的部分用遮在红色三角形内部,右下角的部分遮在蓝色三角形内部即可。
之前我们知道如何把图片的一部分遮住,现在稍显复杂,遮蔽的并非图片而是一个图层。我们定义bg0图层来放背景,bg1放烈,bg2放百百世,图片四张,其中vs_tl.png和vs_br.png只是用来当遮罩的。

代码如下,这段代码每次战斗回都会用,所以后来也被我包装成可以调的label了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
init python:
def mask_vs_tl(d):
return AlphaMask(d, "vs_tl")
def mask_vs_br(d):
return AlphaMask(d, "vs_br")
scene black with dissolve
show layer bg1 at mask_vs_tl
show layer bg2 at mask_vs_br
show white with Dissolve(0.25)
pause 0.5
hide black with None
hide white
show vs_w onlayer bg0
with dissolve
show 烈 灌注全灵 onlayer bg1:
zoom 1.2
xanchor 0.5
yanchor 0.5
xpos 0.5
ypos 0.75
alpha 0.0
ease 0.7 xpos 0.3 ypos 0.525 alpha 1.0
linear 1.6 xpos 0.2 ypos 0.475
ease 0.7 xpos 0.0 ypos 0.25 alpha 0.0
show 姬虫百百世 笑 onlayer bg2:
zoom 1.25
xanchor 0.5
yanchor 0.2
xpos 0.5
ypos 0.25
alpha 0.0
ease 0.7 xpos 0.7 ypos 0.475 alpha 1.0
linear 1.6 xpos 0.8 ypos 0.525
ease 0.7 xpos 1.0 ypos 0.75 alpha 0.0
pause 0.6
show vs_vs:
xalign 0.5 yalign 0.5
zoom 2.0
alpha 0.0
easeout 0.5 zoom 1.0 alpha 1.0
pause 0.5
with Shake((0, 0, 0, 0), 0.3, dist=20)
pause 0.1
scene black with dissolve
hide 烈 onlayer bg1
hide 姬虫百百世 onlayer bg2
hide vs_w onlayer bg0
这里的Shake是从这里扒来的,可以实现一个随机的抖动。和vpunch与hpunch一样,底层去调renpy/display/motion.py中的Motion类,来让整个界面晃起来。这是定义在renpy/common/00definitions.rpy下的其他一些转场:
1
2
3
4
5
6
7
8
9
10
11
12
13
# Zoom-based transitions. Legacy - nowadays, these are probably best done with ATL.
define zoomin = OldMoveTransition(0.5, enter_factory=ZoomInOut(0.01, 1.0))
define zoomout = OldMoveTransition(0.5, leave_factory=ZoomInOut(1.0, 0.01))
define zoominout = OldMoveTransition(0.5, enter_factory=ZoomInOut(0.01, 1.0), leave_factory=ZoomInOut(1.0, 0.01))
# These shake the screen up and down for a quarter second.
# The delay needs to be an integer multiple of the period.
define vpunch = Move((0, 10), (0, -10), .10, bounce=True, repeat=True, delay=.275)
define hpunch = Move((15, 0), (-15, 0), .10, bounce=True, repeat=True, delay=.275)
# These use the ImageDissolve to do some nifty effects.
define blinds = ImageDissolve(im.Tile("blindstile.png"), 1.0, 8)
define squares = ImageDissolve(im.Tile("squarestile.png"), 1.0, 256)
其他内容
文本着色器
巫女是红白,魔法使是黑白,东方里有许多角色都有一个或者两个主色调,但是偏偏有什么七色的人偶师,七曜的魔女,七彩的LED翅膀,还有个彩虹上的市场神,这让我在选择文字配色上犯了难。Ren’Py仅能允许我们修改文字的填充色和边框色,那我们只好期待让不同字之间产生颜色梯度,给人一种彩虹渐变的感觉。

实现事实上并不困难,我们知道总字数,就可以给每个字分配一个颜色,以下的代码来自这里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# Takes in two colors, a range and an index and interpolates a new color
# between the start and end points based on the range and index.
# color_1: (String of hex color in #rrggbb format) Start of the gradient
# color_2: (Same as above) End of the gradient
# range: (int) The number of elements in the gradient
# id: (int) The offset into the gradient's range
# Return: String of interpolated hex color in rrggbb format
def color_gradient(color_1, color_2, range, index):
if index == 0:
return color_1
if range == index:
return color_2
start_col = Color(color_1)
end_col = Color(color_2)
return start_col.interpolate(end_col, index * 1.0/range).hexcode
# Applies a static gradient over text
# Note: Hex Color = A string giving a hexadecimal color, in the form "#rrggbb".
# color_1: (Hex Color) The starting color
# color_2: (Hex Color) The ending color
# Args are separated by an '-'
# Example: {gradient=[color_1]-[color_2]}{/gradient}
def gradient_tag(tag, argument, contents):
new_list = [ ]
if argument == "":
return
else: # Note: all arguments must be supplied
col_1, _, col_2 = argument.partition('-')
# Get a count of all the letters we will be applying colors to
count = 0
for kind,text in contents:
if kind == renpy.TEXT_TEXT:
for char in text:
if char == ' ':
continue
count += 1
count -= 1
my_index = 0
my_style = DispTextStyle()
for kind,text in contents:
if kind == renpy.TEXT_TEXT:
for char in text:
if char == ' ':
new_list.append((renpy.TEXT_TEXT, ' '))
continue
new_list.append((renpy.TEXT_TAG, "color=" + color_gradient(col_1, col_2, count, my_index)))
new_list.append((renpy.TEXT_TEXT, char))
new_list.append((renpy.TEXT_TAG, "/color"))
my_index += 1
elif kind == renpy.TEXT_TAG:
if not my_style.add_tags(text):
new_list.append((kind, text))
else:
new_list.append((kind,text))
return new_list
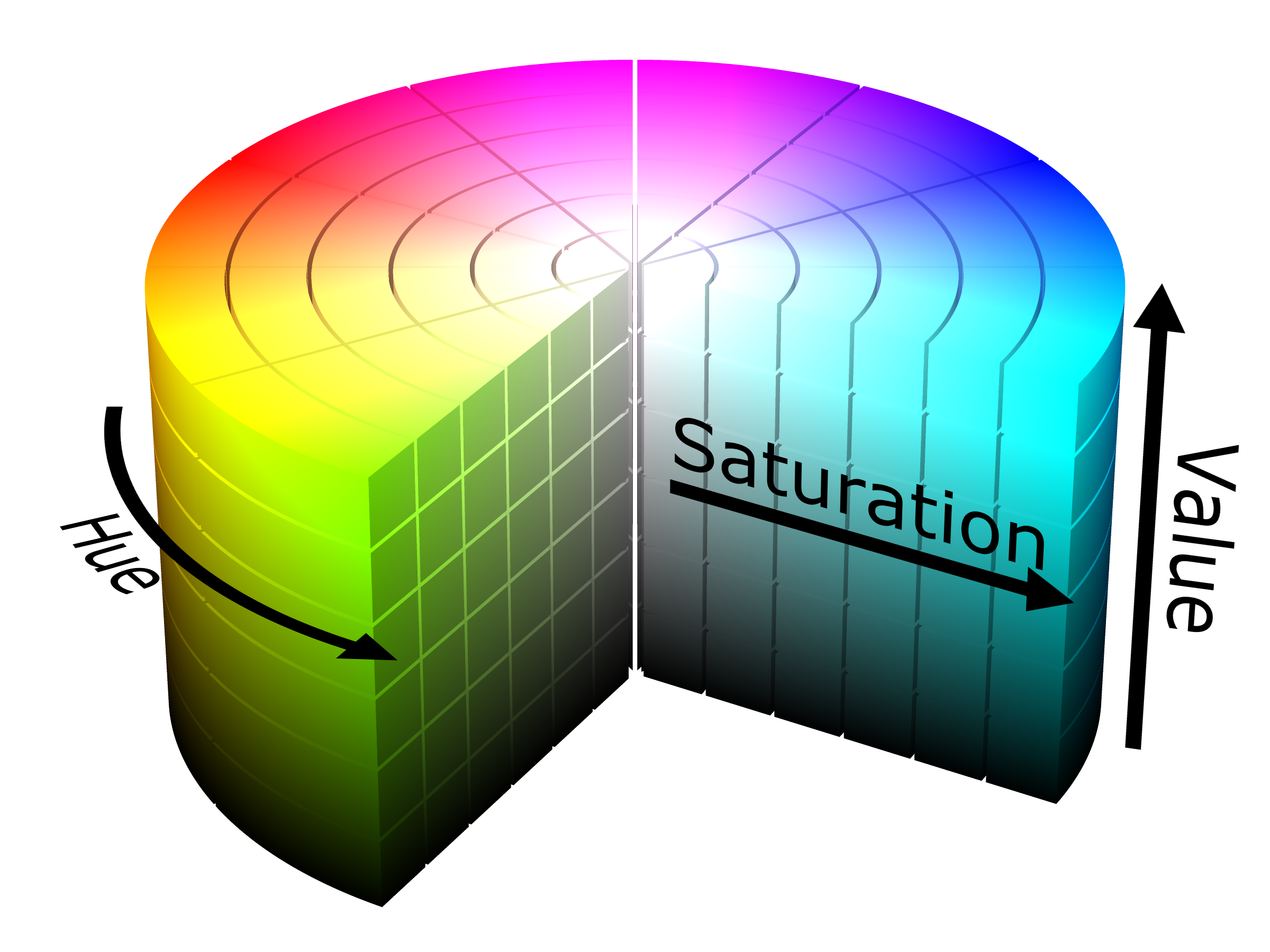
Color类的插值默认是在RGB空间进行的,所以你可能会觉得中间的颜色饱和度没有首尾两端高。这是HSV空间的颜色示意图,如果我们从红色区域连到蓝色,走直线的话就会很接近中间的白色区域,而沿着色相环走的话就能经过粉色、紫色到蓝色,一直保持鲜艳。Ren’Py的Color类也提供了在其它空间插值的办法,调用interpolate_hsv()即可。函数原型可以在renpy/color.py中找到。

这样的过渡有两个问题,首先是多行文字行与行之间颜色差距比较大,其次其实这种过渡是发生在字与字之间的,字数越多这种过渡越平滑,只有一个字的时候就看不出过渡来了。换句话说我们想要每个字内部有渐变,最好是垂直渐变,就像这样:

这就不是color这个标签能做到的了,我们需要认识一下着色器。所谓着色器大致而言就是运行在GPU上的小程序,以可并行为最大特点。

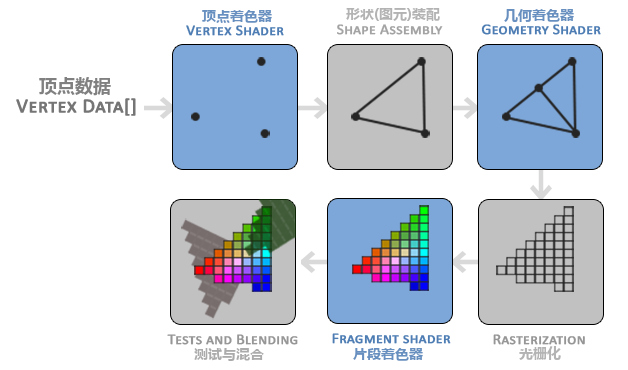
假设我们想在屏幕上绘制一个立方体,并给它上色,大致如上图所示(顺带一提这张图展示了RGB颜色空间)。那么绘制过程中最重要的有两步:第一步,确定立方体的每一个顶点在屏幕上的位置;第二步,屏幕上的每一个像素,根据它的位置,计算出它应该对应到立方体的哪个位置,再根据这个位置计算它应该显示什么颜色。渲染管线中还有很多步骤和细节,但最核心的就是这两步了。注意到,这个过程其实是可以并行的,每个顶点所在的位置只跟自己的位置和摄像机有关,和其他顶点无关,并且每个顶点计算位置的这个程序是共通的,和它是哪个顶点无关。所以如果是CPU来运行这段代码,需要循环遍历8个顶点来计算出自己的位置,但如果我们同时运行8个程序,就可以同时计算出8个结果来。第二步着色就更是如此了,每个像素的颜色,只和像素的位置有关,而与其他像素无关,所以所有像素都可以同时计算自己的颜色,这就可以仰赖GPU的并行计算能力了。那么,计算顶点位置和计算颜色的小程序,就是顶点着色器和片段着色器,一个渲染任务先经过顶点着色器算出顶点位置,再通过片段着色器算出颜色,才能显示在屏幕上。
着色器的程序是运行在GPU上的,需要使用GLSL这门编程语言来写,不过我们只需关注进入着色器的变量与着色器输出的变量,以及二者之间的数学关系,至于语法等等死板的东西交给AI即可。
我们先来看Ren’Py预定义的一个名为wave的着色器:
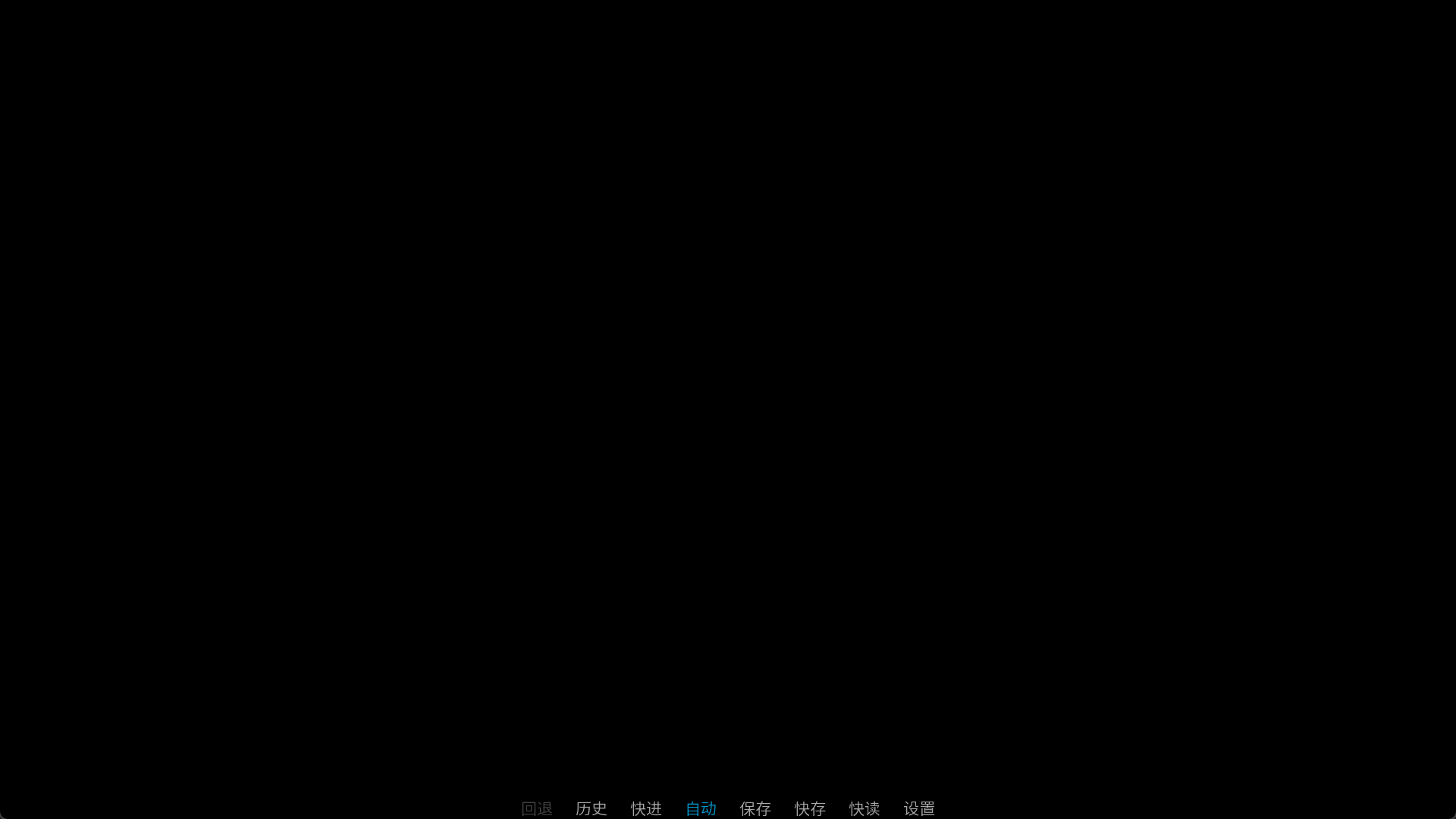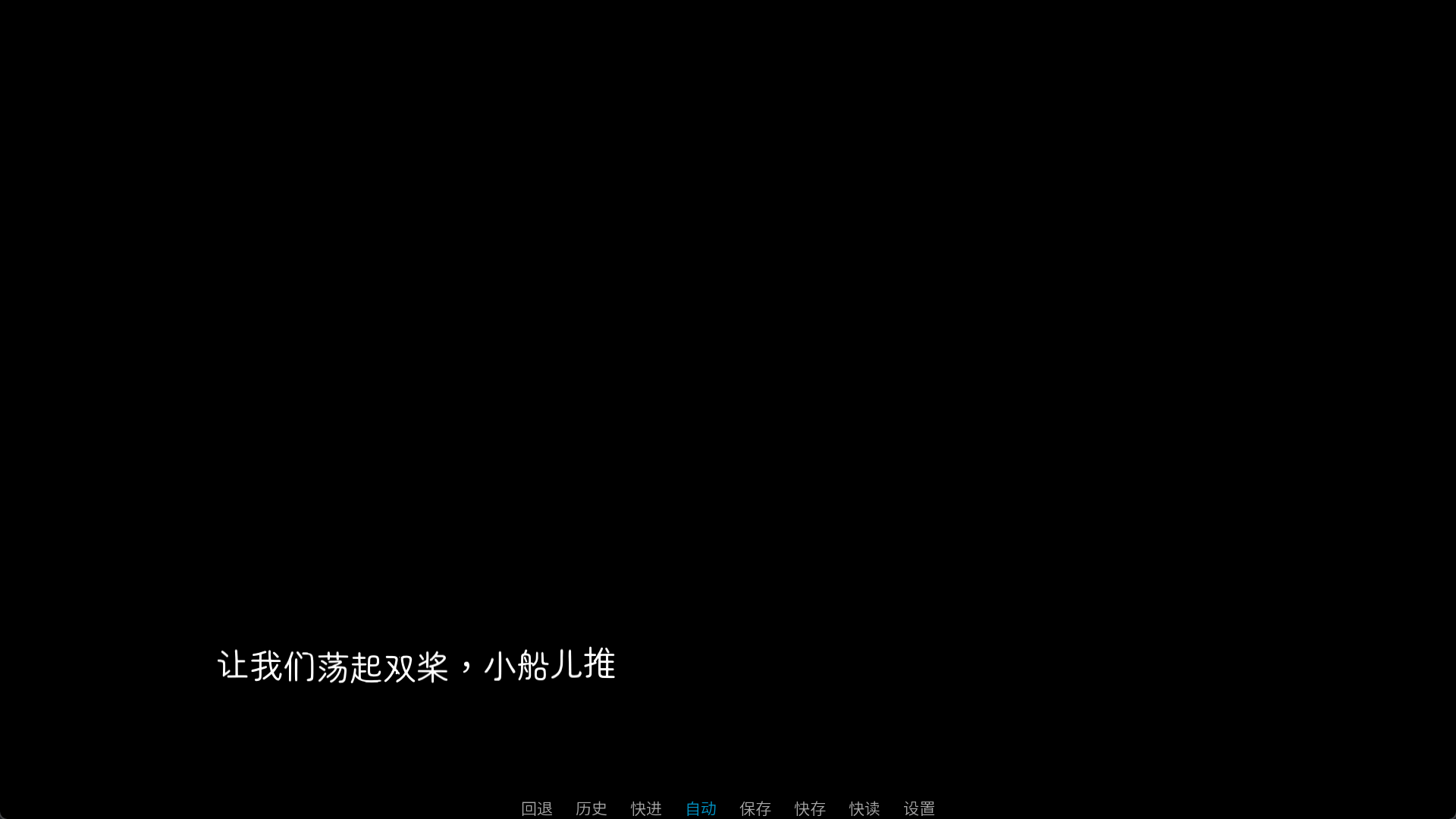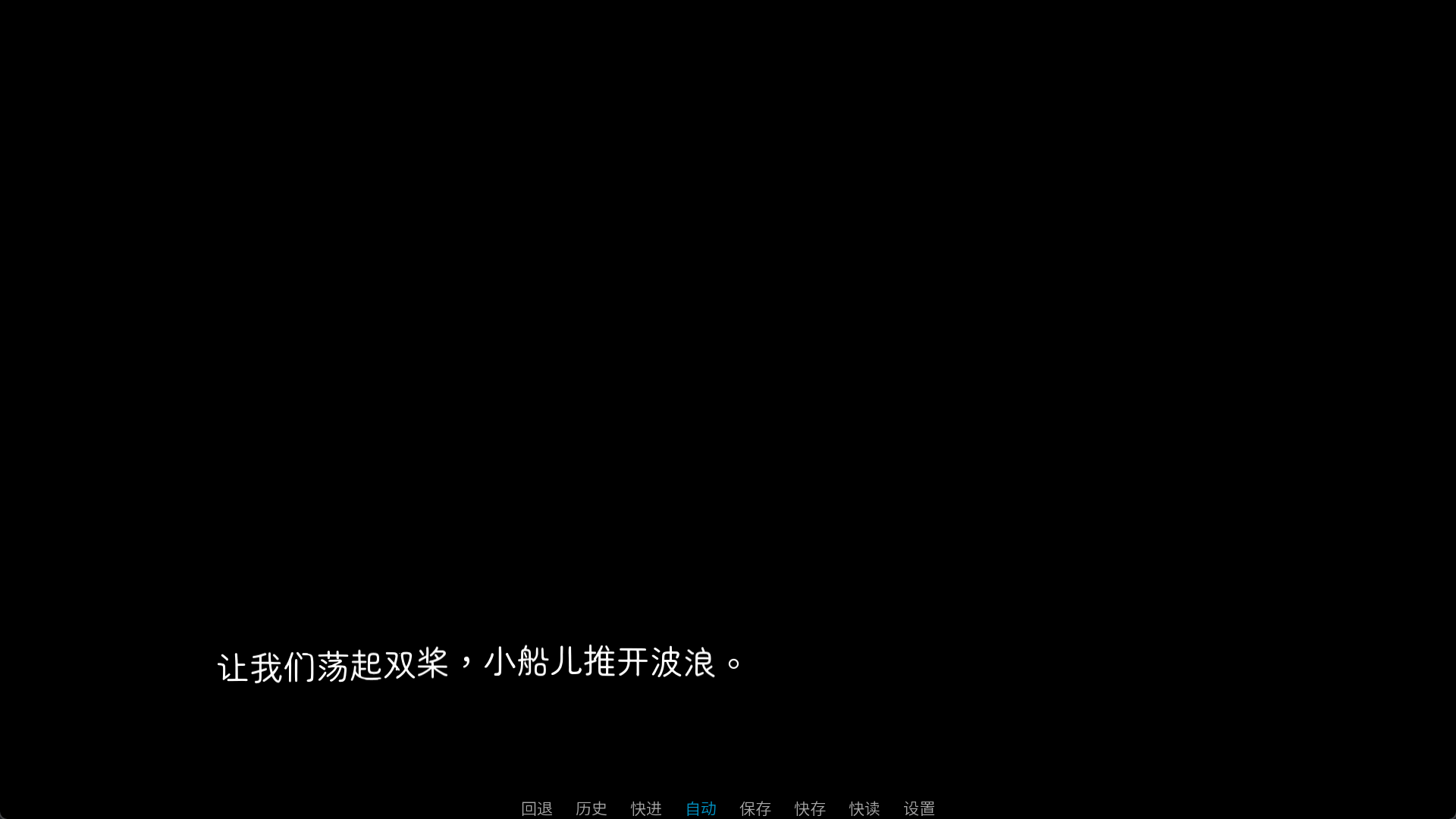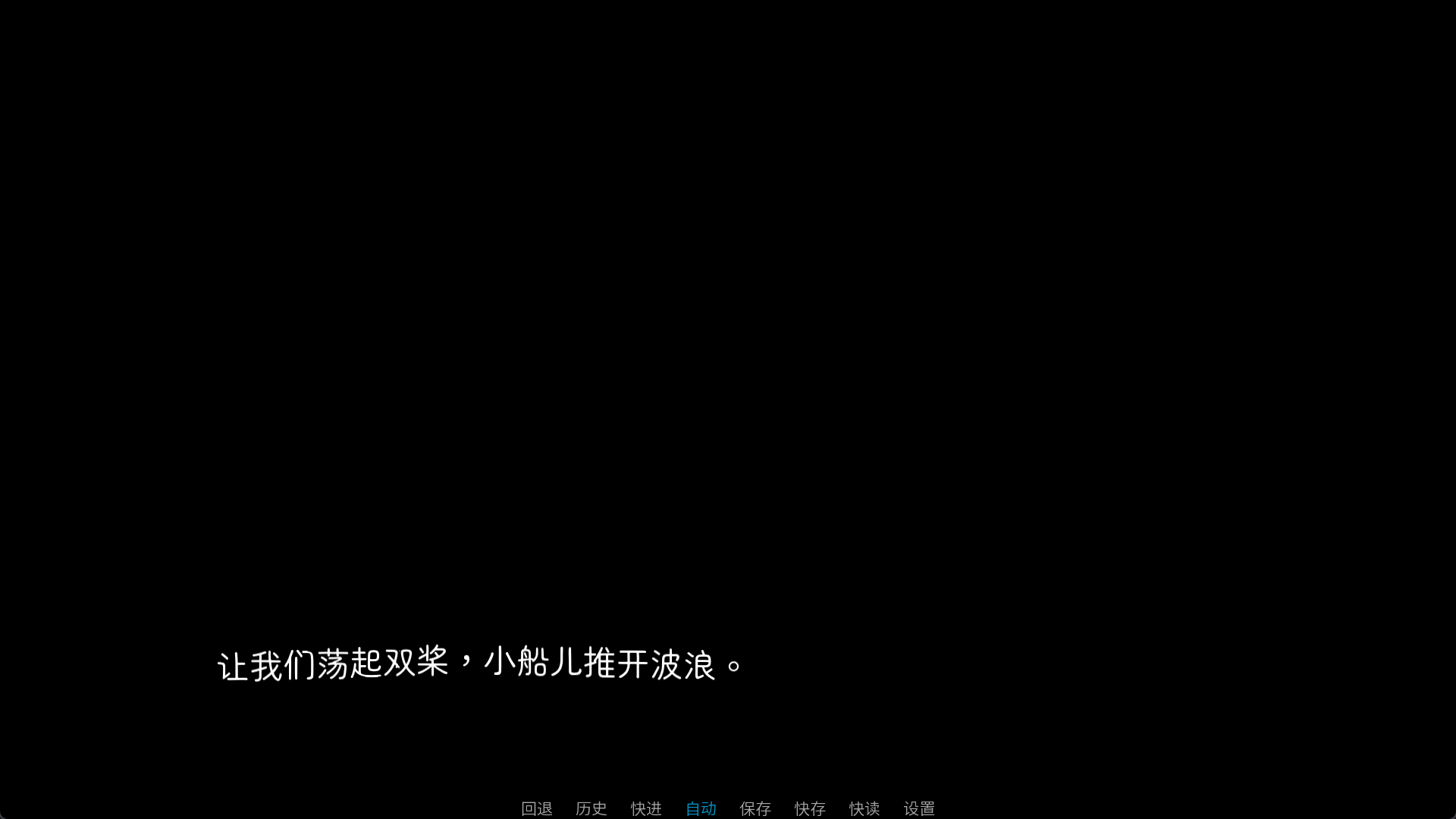
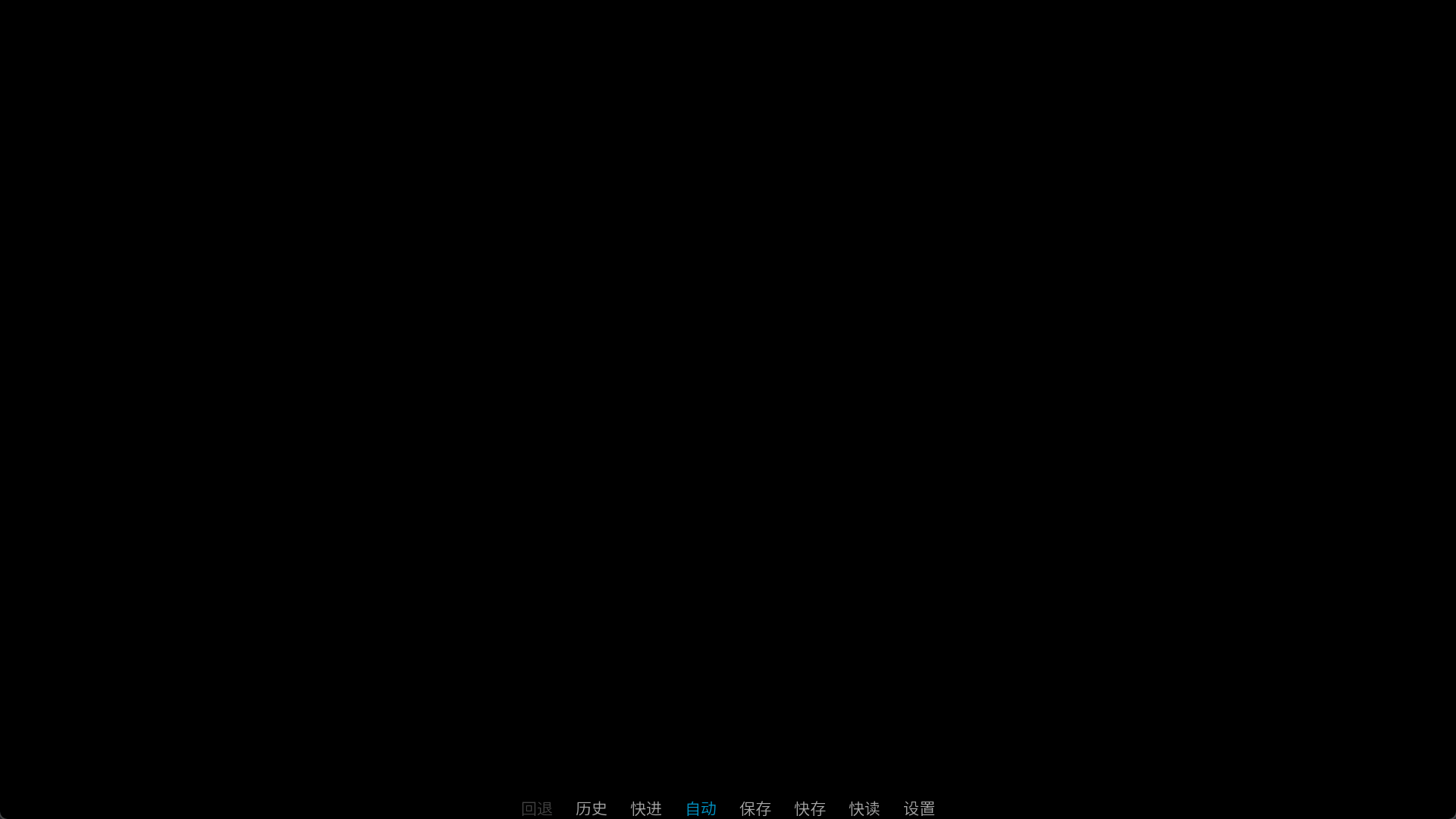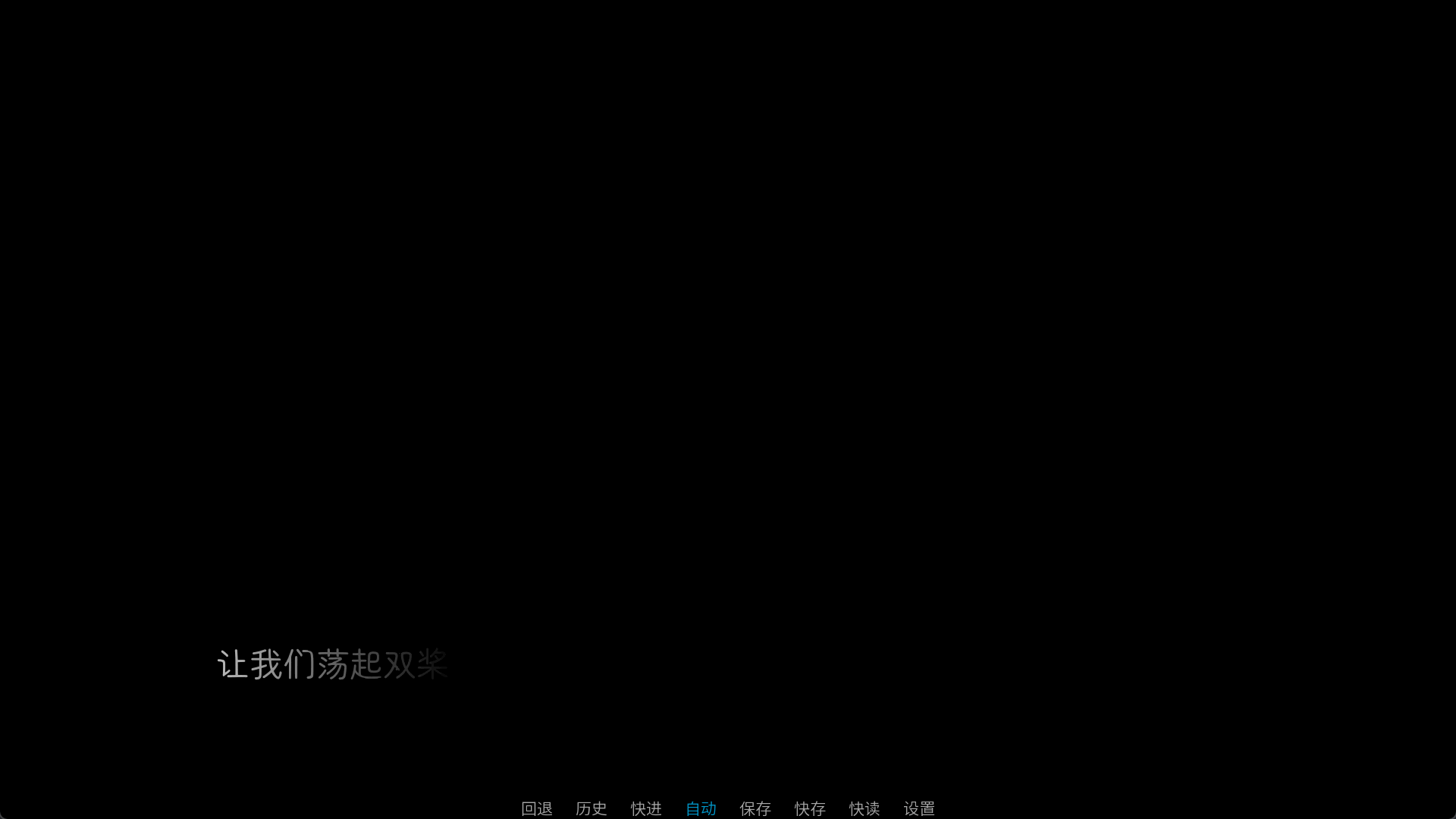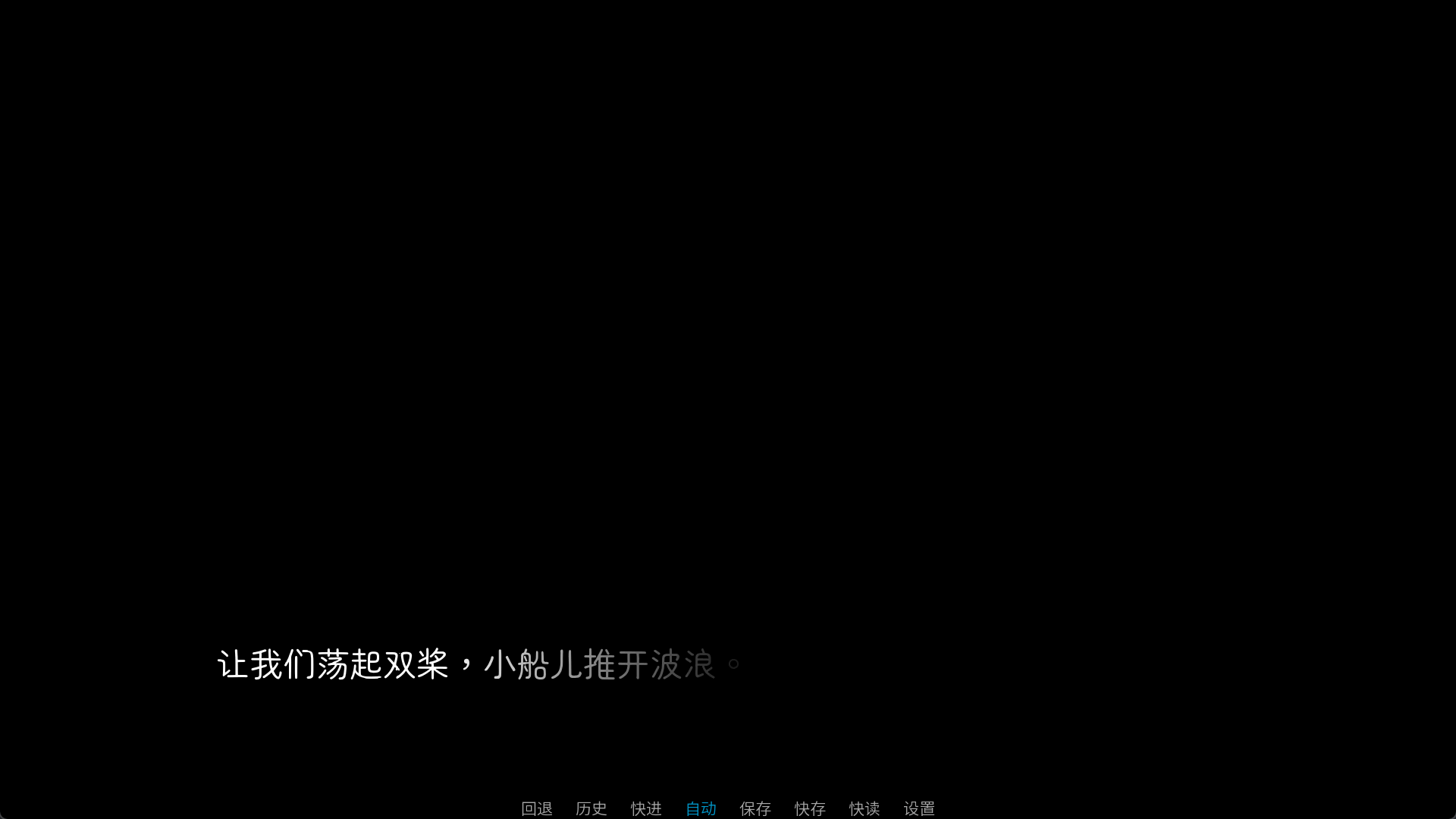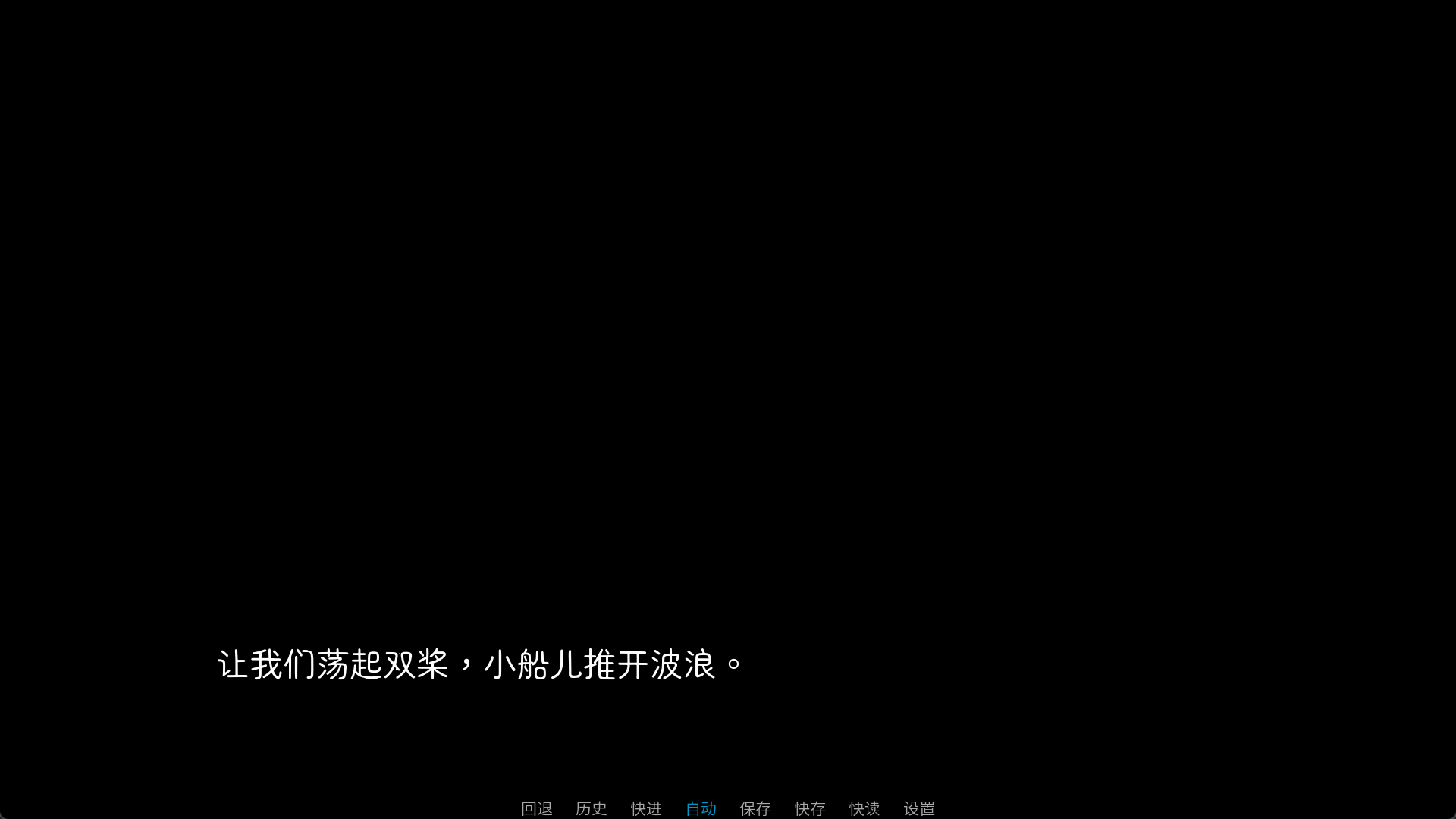
如果要用文本标签使用着色器,应当先设置默认着色器,typewriter是打字机效果,可以先把它设置为默认着色器。
1
2
define config.default_textshader = 'typewriter'
"{shader=wave}让我们荡起双桨,小船儿推开波浪。{/shader}"
着色器中的变量类型有三种,attribute表示该点自己的属性,例如某个字的自己的位置;uniform是大家共用的,在全过程保持不变的数据,例如摇晃的频率、振幅等等;varying是顶点着色器传递给片段着色器的变量。在着色器中可以直接使用的变量可以参考文档。
在这个例子中,我们需要使用如下的变量:
1
2
3
4
5
6
7
uniform float u__amplitude; // 震荡的振幅,单位为像素
uniform float u__frequency; // 震荡的频率,单位为赫兹
uniform float u__wavelength; // 震荡的波长,一个波峰到波峰之间的字数
uniform float u_time; // 当前时间,单位为秒
uniform float u_text_to_drawable; // 当前窗口的虚拟像素向真正屏幕的像素转换缩放的比例
attribute float a_text_index; // 当前字在文本中的索引,从0开始
每个字的顶点是字体库决定的,我们不需考虑,我们只要每个字的每个顶点,按照字的位置和时间,上下移动自己的位置即可。这里按照编程风格规范,用户自定义的变量加两个下划线,一个下划线的是Ren’Py定义的变量,gl开头的变量是OpenGL定义的变量,可以参考这里,我们要改变顶点的位置,这里使用到的是vec4 gl_Position,可以直接用gl_Position.y操作它的y分量,非常方便。
1
gl_Position.y += cos(2.0 * 3.14159265359 * (a_text_index / u__wavelength + u_time * u__frequency)) * u__amplitude * u_text_to_drawable;
来看第二个预定义的着色器dissolve。
我们需要将当前时间传递给片段着色器,然后在片段着色器里设置透明度。计算透明度需要知道打字的快慢和溶解的快慢,综上所述需要定义的变量如下:
1
2
3
4
5
uniform float u__duration; // 完全溶解所需要的时间相当于打多少个字,相当于同一时刻透明度在改变的字符的数量
uniform float u_text_slow_duration; // 打字速度,设置为0表示不使用打字机效果
uniform float u_text_slow_time; // 打字所经过的时间,所有字都打出或玩家点击文本跳过时会输出最大值
attribute float a_text_time; // 当前字应被打出的时间
varying float v_text_time; // 在顶点着色器内将a_text_time传递给片段着色器
顶点着色器:
1
v_text_time = a_text_time;
片段着色器:
1
2
3
4
5
6
7
8
float l__duration = u__duration * u_text_slow_duration;
float l__done;
if (l__duration > 0.0) {
l__done = clamp((u_text_slow_time - v_text_time) / l__duration, 0.0, 1.0);
} else {
l__done = v_text_time <= u_text_slow_time ? 1.0 : 0.0;
}
gl_FragColor = gl_FragColor * l__done;
这里要修改的vec4 gl_FragColor就是每个像素对应的颜色了。局部变量的命名风格是以l开头。
现在我们已经有能力实现一开始的垂直方向颜色渐变了。使用的变量可以参考文档中有关文本着色器和基于模型的渲染器的部分。
变量:
1
2
3
4
5
6
uniform vec4 u__color_top; // 渐变起始颜色
uniform vec4 u__color_bottom; // 渐变结束颜色
uniform vec2 u_model_size; // 整个文本的总尺寸
attribute vec2 a_text_center; // 每个字的baseline的中心坐标,单位为屏幕像素
attribute vec4 a_position; // 顶点的位置,单位为窗口的虚拟像素
varying float v__gridient_done; // 顶点的颜色的过渡比例,取值范围为0到1
顶点着色器:
1
v__gridient_done = a_position.y / u_model_size.y;
片段着色器:
1
gl_FragColor *= mix(u_gradient_color_top, u_gradient_color_bottom, v__gridient_done); // mix是线性插值函数
当然,我倾向于使用hsv空间插值,我不太知道有没有现成的方法可以直接使用,所以直接在着色器里进行这个转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
float gradient_done = v_gradient_done;
// hsv_top = rgb2hsv(u_gradient_color_top.rgb)
vec3 c1 = u_gradient_color_top.rgb;
vec4 K1 = vec4(0.0, -1.0/3.0, 2.0/3.0, -1.0);
vec4 p1 = mix(vec4(c1.bg, K1.wz), vec4(c1.gb, K1.xy), step(c1.b, c1.g));
vec4 q1 = mix(vec4(p1.xyw, c1.r), vec4(c1.r, p1.yzx), step(p1.x, c1.r));
float d1 = q1.x - min(q1.w, q1.y);
float e1 = 1.0e-10;
vec3 hsv_top = vec3(abs(q1.z + (q1.w - q1.y) / (6.0*d1 + e1)),
d1 / (q1.x + e1),
q1.x);
// hsv_bottom = rgb2hsv(u_gradient_color_bottom.rgb)
vec3 c2 = u_gradient_color_bottom.rgb;
vec4 K2 = vec4(0.0, -1.0/3.0, 2.0/3.0, -1.0);
vec4 p2 = mix(vec4(c2.bg, K2.wz), vec4(c2.gb, K2.xy), step(c2.b, c2.g));
vec4 q2 = mix(vec4(p2.xyw, c2.r), vec4(c2.r, p2.yzx), step(p2.x, c2.r));
float d2 = q2.x - min(q2.w, q2.y);
float e2 = 1.0e-10;
vec3 hsv_bottom = vec3(abs(q2.z + (q2.w - q2.y) / (6.0*d2 + e2)),
d2 / (q2.x + e2),
q2.x);
vec3 hsv_mix = mix(hsv_top, hsv_bottom, gradient_done);
// rgb = hsv2rgb(hsv_mix)
vec3 k = vec3(1.0, 2.0/3.0, 1.0/3.0);
vec3 p = abs(mod(hsv_mix.xxx + k, 1.0) * 6.0 - 3.0) - 1.0;
vec3 rgb = hsv_mix.z * mix(k.xxx, clamp(p, 0.0, 1.0), hsv_mix.y);
float alpha = mix(u_gradient_color_top.a, u_gradient_color_bottom.a, gradient_done);
gl_FragColor *= mix(u_gradient_color_top, u_gradient_color_bottom, v_gradient_done);
最后,我们来看一下变量声明、顶点着色器、片段着色器如何在Ren’Py中注册并使用,下面是一个旋转效果的文本着色器,GLSL将会以纯文本的方式传给:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
init python:
def adjust_extra_slow_time(ts, u__delay, **kwargs):
"""
调整文本着色器的额外显示时间
"""
ts.extra_slow_time = u__delay
renpy.register_textshader(
"spin", # 着色器名
# 传给文本着色器的uniform变量会先使用该函数处理,该函数可以设置来源对象的extra_slow_time、extra_slow_duration、redraw、redraw_when_slow这四个字段。
adjust_function = adjust_extra_slow_time,
variables = """
uniform float u__delay;
uniform float u__offset;
uniform float u_text_slow_time;
attribute vec2 a_text_center;
attribute float a_text_min_time; // 字的最左端显示的时间
""",
# 这里的50是优先级
# 100时几何着色 顶点修改要在那之前
# 200时才会初始化gl_FragColor 颜色修改要在那之后
vertex_50 = """
float l__angle = clamp((u_text_slow_time - a_text_min_time) / u__delay, 0.0, 1.0) * 2.0 * 3.1415926536;
float l__sin = sin(l__angle);
float l__cos = cos(l__angle);
gl_Position.y -= u__offset;
gl_Position.xy -= a_text_center;
gl_Position = vec4(
gl_Position.x * l__cos - gl_Position.y * l__sin,
gl_Position.x * l__sin + gl_Position.y * l__cos,
gl_Position.z,
gl_Position.w
);
gl_Position.xy += a_text_center;
gl_Position.y += u__offset;
""",
u__delay = 1.0, # 默认值
u__offset = 0,
)
使用例:
1
"这是一个 {shader=spin:0.5:-5}旋转{/shader} 文本着色器测试。"
其中用冒号来分割各参数。为方便见,我们也可以吧这个着色器的调用专门写成一个自定义标签。
更多的有关文本着色器的知识,以及Ren’Py预定义的文本着色器,可以参考文档。
着色器
那么,文本着色器实质上是把文本当做一个图形要显示在屏幕上,那自然显示一个图形也是非常简单的了。注册文本着色器使用的是register_textshader(),注册着色器使用register_shader(),二者的参数都是相似的,所以这里就不多说了。
1
2
3
4
5
renpy.register_shader(name, **kwargs)
# name 着色器名
# variables 着色器变量声明
# vertex_functions 顶点着色器函数
# fragment_functions 片段着色器函数
不过我发动我贫瘠的想象力也没想到这个有什么用,唯一的尝试是在伪天棚那里做了个背景,显然是仿zun先生的效果的:

具体而言,平面上的任何线性变换,都只会把平行四边形变成平行四边形,然而我们的视觉在看到远处的事物的时候,是会有近大远小的效果的,换句话说,一个正方形在我们的眼里可能会变成一个梯形。那么要怎么干这个事呢?其实相当简单,我们只要算好怎么把这个正方形的四个顶点投影到屏幕的梯形的四个顶点上就好,其实游戏内部的空间本身就是三维的,我们只要算好从摄像机里看去,投影这些点所用的投影矩阵就好。
我说是正方形确实是正方形,zun先生在虹龙洞里使用的图片就是这一张,整个背景就是这张图不停地在自我循环(可以打开游戏看一下):
首先,一个点的坐标一般是四维向量,这样方便我们平移,多余的这个1我们稍后还会用到:
\[\left[\begin{array}{} 1&0&0&T_x\\ 0&1&0&T_y\\ 0&0&1&T_z\\ 0&0&0&1 \end{array}\right] \left(\begin{array}{} x\\y\\z\\1 \end{array}\right)= \left(\begin{array}{} x+T_x\\y+T_y\\z+T_z\\1 \end{array}\right)\]那么现在要做的就是,就是求出以下线性变换的矩阵
- 把物体放在世界位置的平移和旋转矩阵(模型矩阵)
- 把世界相对于摄像机的平移和旋转矩阵(观察矩阵)
- 把正交投影改成透视投影矩阵(投影矩阵)
- 把坐标系改成屏幕坐标系
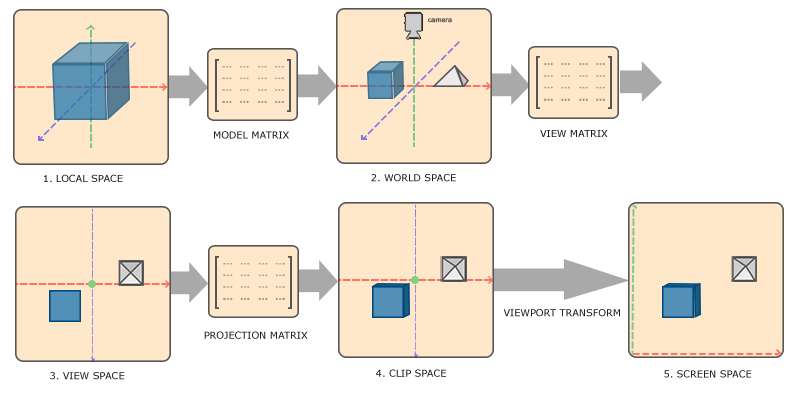
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
image white_fog_full:
"#c6d5f4"
show white_fog_full zorder 15 with fur
transform fogshader:
shader "xyz.fogshader"
# 198 213 244 c6d5f4
u_gradient_top (198/256, 213/256, 244/256, 1.0)
u_gradient_bottom (0, 0, 0 , 0)
image white_fog:
"#c6d5f4"
fogshader
init python:
# a_position 图片的坐标 左上角为原点 像素为单位
# u_totalmatrix project_matrix * view_matrix
# u_transform 将图片的坐标转化为Ren'Py的标准化设备坐标 取值-1到+1 多余裁剪
# y轴和-z轴互换
# x右 y上 z后
# 乘上观察矩阵和投影矩阵 现在变为透视投影
renpy.register_shader("xyz.floorshader", variables="""
attribute vec4 a_position;
uniform mat4 u_totalmatrix;
uniform mat4 u_transform;
""", vertex_300="""
gl_Position = u_transform * a_position;
gl_Position.z = -gl_Position.y;
gl_Position.y = -1.0;
gl_Position = u_totalmatrix * gl_Position;
""")
renpy.register_shader("xyz.fogshader", variables="""
uniform vec4 u_gradient_top;
uniform vec4 u_gradient_bottom;
uniform vec2 u_model_size;
varying float v_gradient_done;
attribute vec4 a_position;
""", vertex_300="""
v_gradient_done = 2 * a_position.y / u_model_size.y;
""", fragment_300="""
gl_FragColor *= mix(u_gradient_top, u_gradient_bottom, v_gradient_done);
""")
$ eye = (0,2,3.8) *5 # 相机位置 2 3.8
$ pos_center = (0,0,0) # 看向原点
$ view_matrix = look_at(eye, pos_center, (0,1,0)) # 观察矩阵
$ project_matrix = perspective(math.radians(28), 1920/1080, 0.1, 100) # 投影矩阵
transform floorshader:
shader"xyz.floorshader"
u_totalmatrix project_matrix * view_matrix
show bg 伪天棚 游戏 as floor0 at floorshader zorder 10:
zoom 20.0
xalign 0.5
yalign 0.5
yoffset 0
linear 20.0 yoffset 10240
repeat
show bg 伪天棚 游戏 as floor1 at floorshader zorder 10:
zoom 20.0
xalign 0.5
yalign 0.5
yoffset -10240
rotate 0
linear 20.0 yoffset 0
repeat
show white_fog zorder 15 with dissolve
pause 2.0
show white_fog_full:
ease 2.0 alpha 0.0
center "~伪天棚~"
hide white_fog_full
hide bg 伪天棚 漫画
"不知今日的山童们在忙些什么,烈海王在路上并没有看到那些身穿迷彩服的小小少女。"
这里的观察矩阵和投影矩阵:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def look_at(eye, center, up):
# 摄像机位置 看向位置 上方
f=normalize((center[0]-eye[0], center[1]-eye[1],center[2]-eye[2]))
s=normalize(cross(f, up))
u=cross(s, f)
return Matrix([s[0], s[1], s[2], -dot(s,eye),
u[0], u[1], u[2], -dot(u,eye),
-f[0], -f[1], -f[2], dot(f, eye),
0, 0, 0, 1])
def perspective(fovy, aspect, zNear, zFar):
# 透视矩阵
tanHalfFovy = math.tan(fovy/2)
ret = [0] * 16
ret[0*4+0]=1/(aspect*tanHalfFovy)
ret[1*4+1]=1/tanHalfFovy
ret[3*4+2]=-1
ret[2*4+2]=-(zFar+zNear)/(zFar-zNear)
ret[2*4+3]=-2*zFar*zNear/(zFar-zNear)
return Matrix(ret)
这里其他矩阵都还好理解,透视矩阵究竟是怎么把台体变成立方体的?还记得坐标其实是一个四维向量吗,最后的$w$坐标实际上会让电脑做一个透视除法:
\[(x', y', z', w') \rightarrow (x'/w', y'/w', z'/w', 1)\]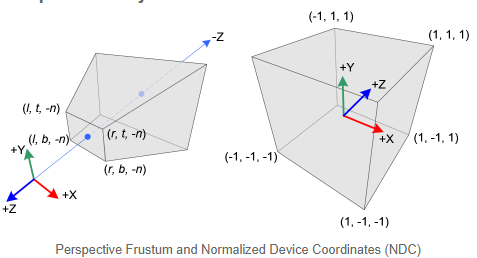
具体的内容就可以去搜一些有关透视除法、投影矩阵的资料。网上一抓一大把。
哦对了,如何让图片自我循环呢,实际上很简单,用两张图片并排在一起向下移动,当上面那张移动到下面的位置时,二者一起向上跳一个图片的高度,看起来就会一直循环了。
最后,我这个实现有一个BUG,按ESC的时候上下会颠倒过来,最终也没有搞清楚是为什么。这种实现方法笨拙而繁杂,于是我后面都是直接播放视频了。视频类其实是一个可视组件,可以参考文档。
1
image HLDGAMEEX = Movie(play="movie/虹龙洞EX面道中裁剪.webm")
样式
文本也不总是写在对话框里,它其实也是一种重要的可视组件。当我们需要像图片一样排布文本时,使用Text组件,其定义在renpy/text/text.py中,具体使用可以参考文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
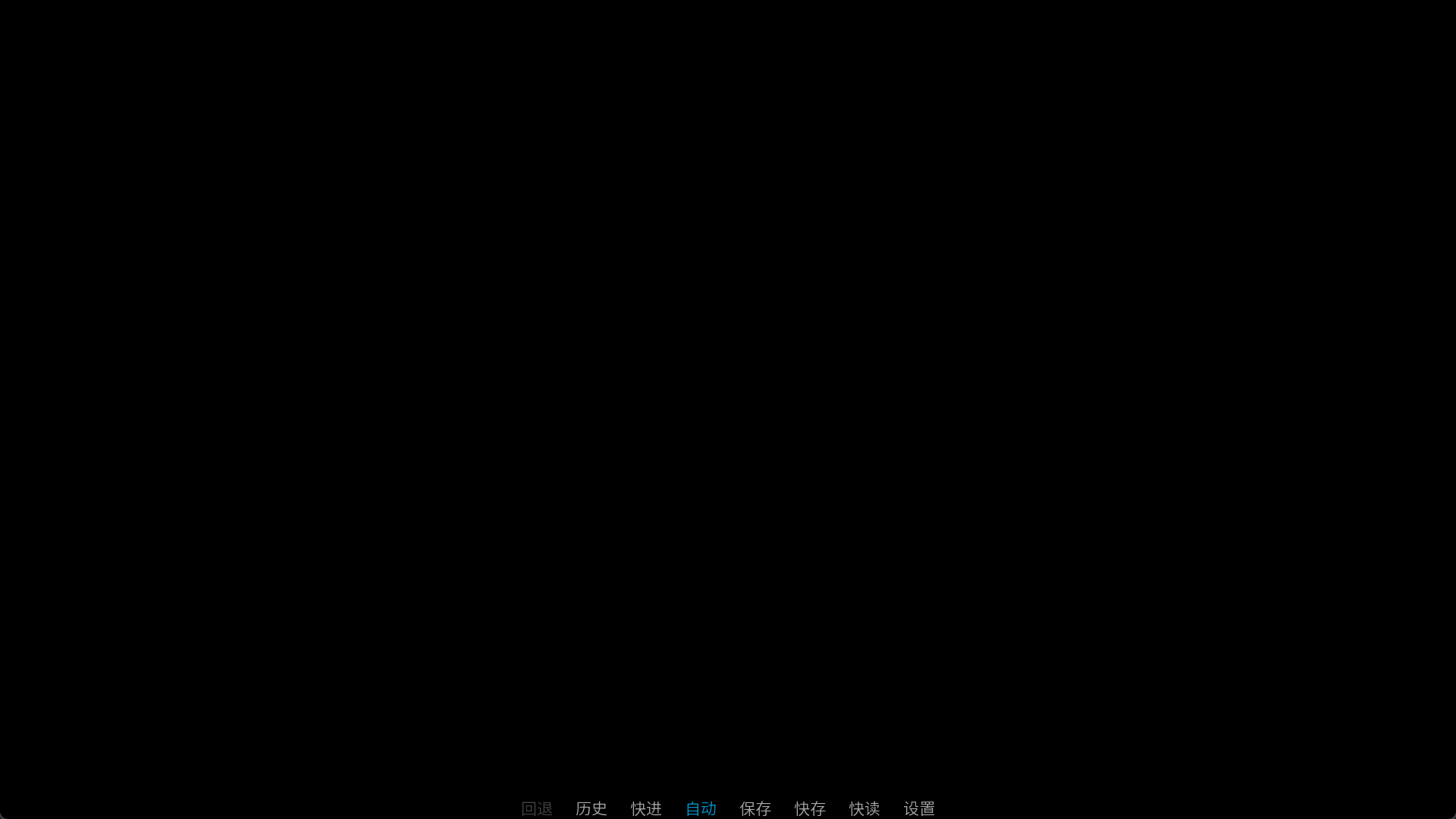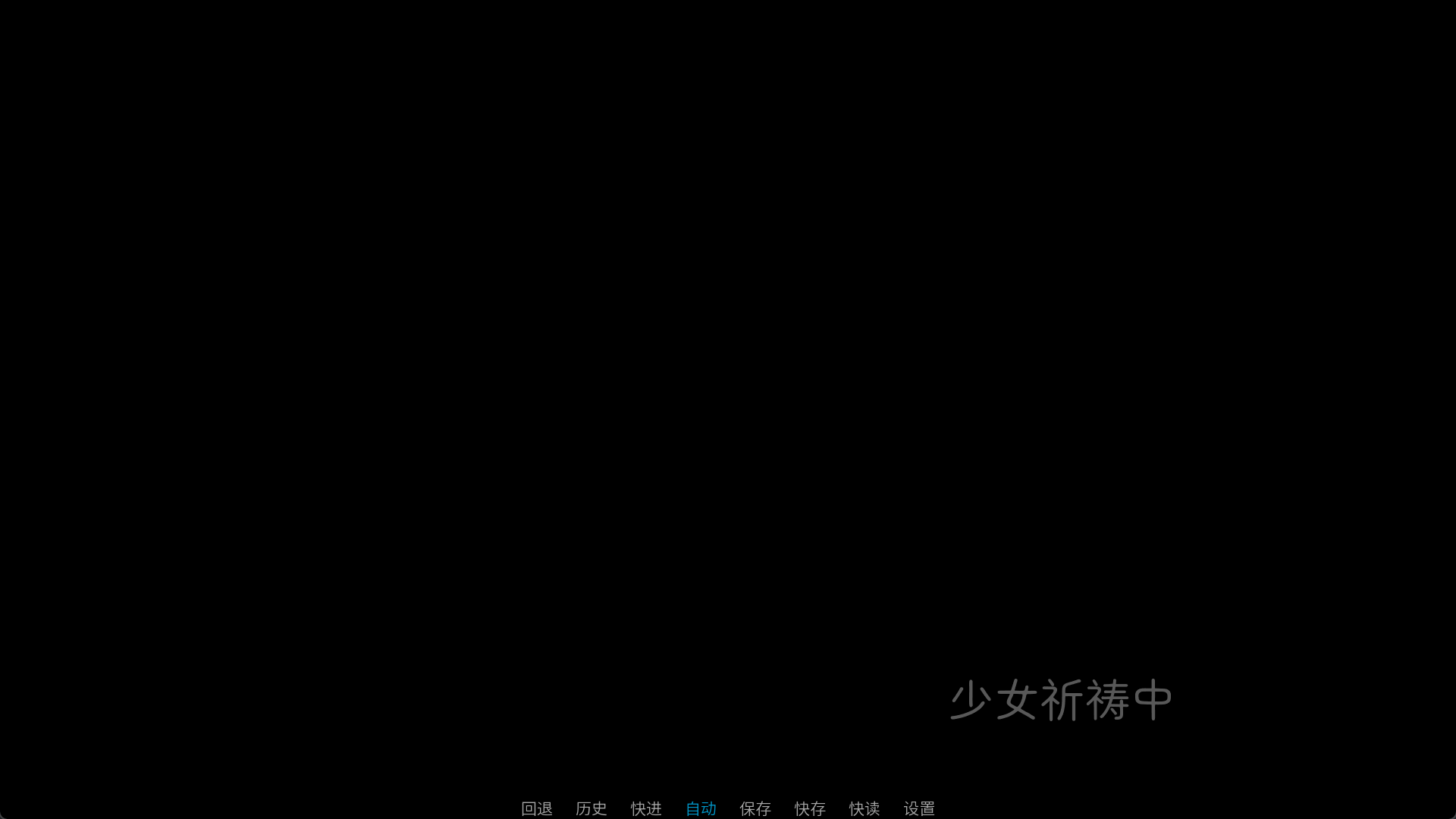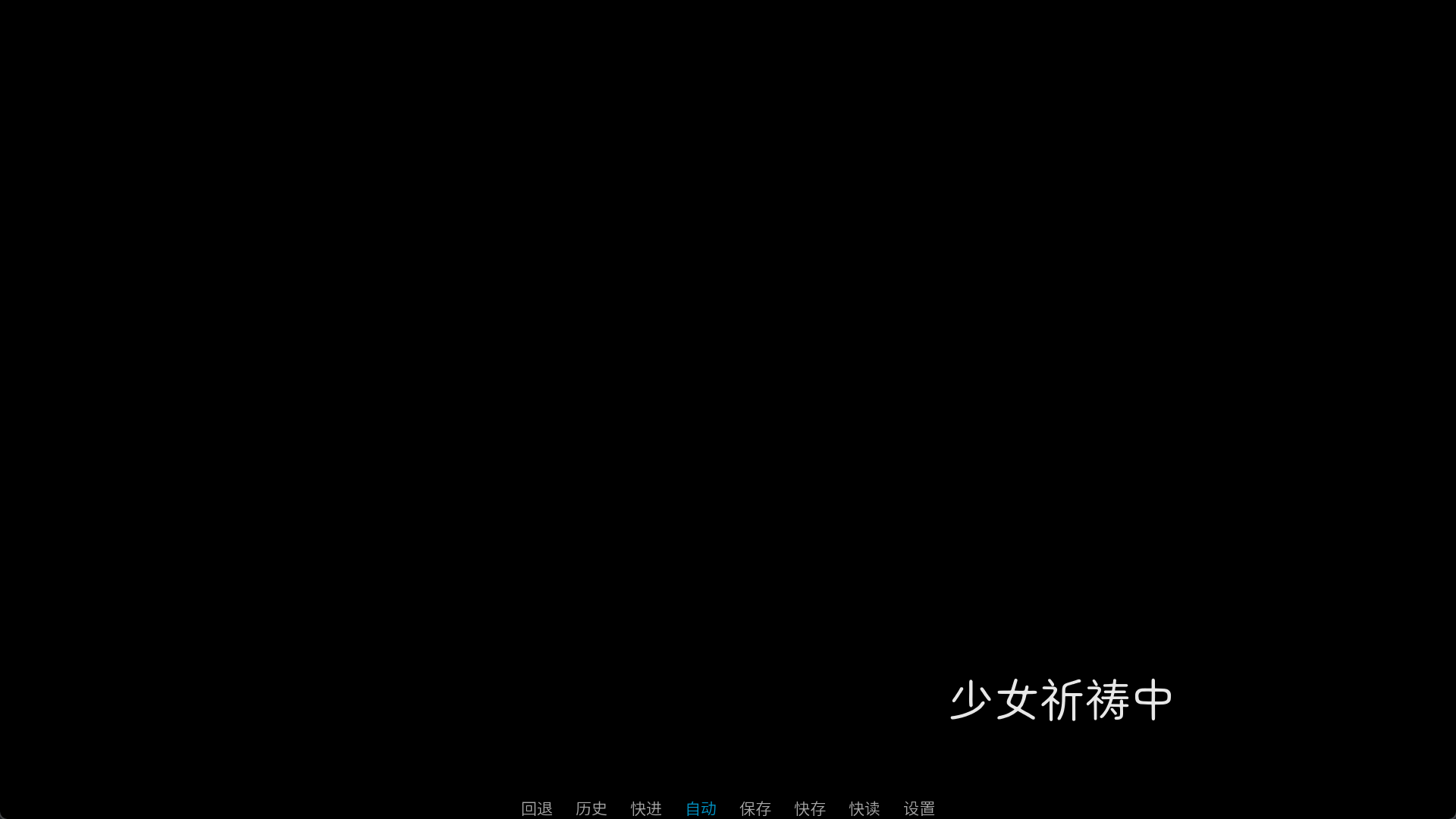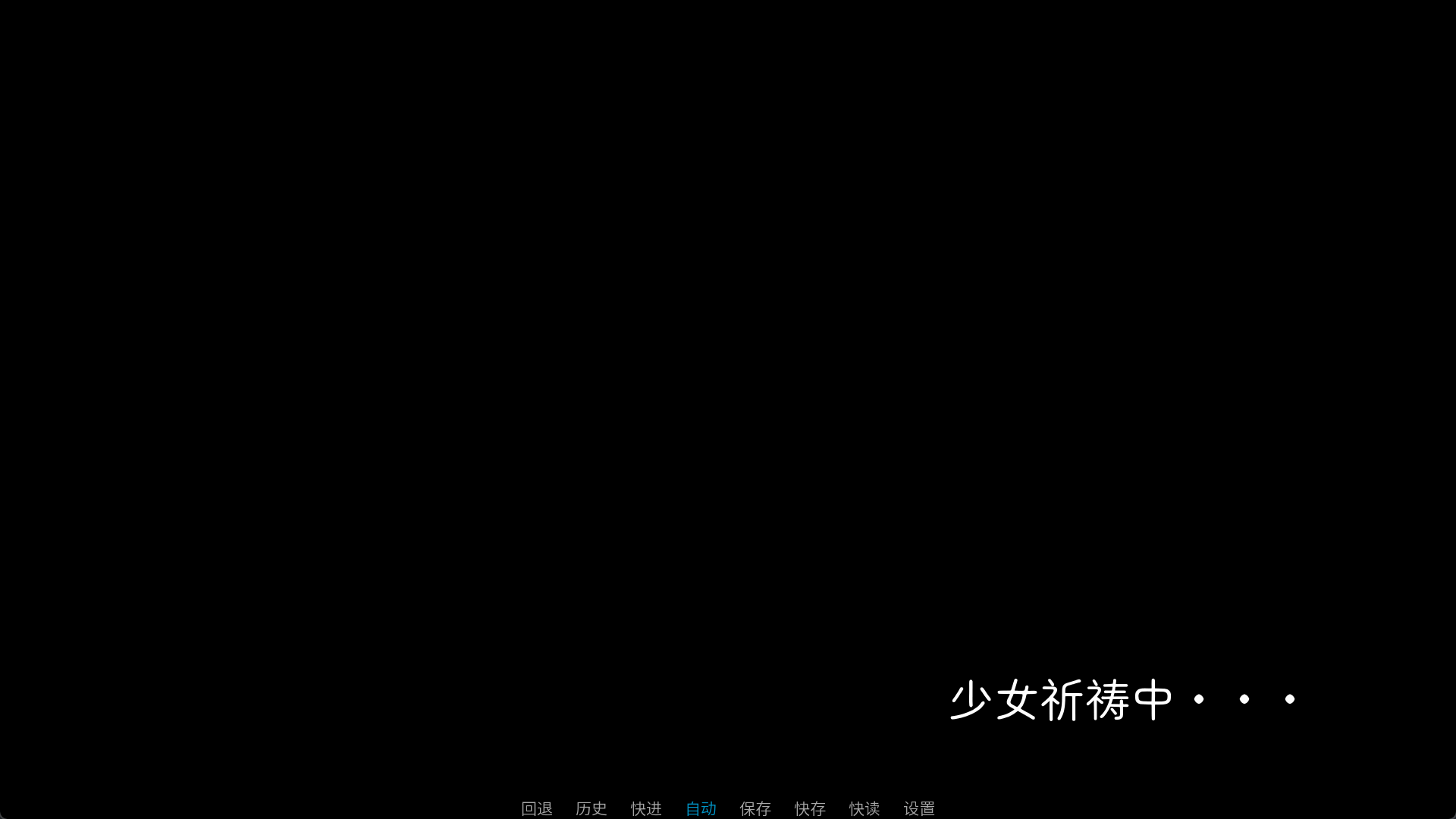
init python:
def shaonvqidaozhong_func(st, at):
nst = int(st) % 4
if nst == 0:
return Text("少女祈祷中", style="SIZE60"), 0.2
if nst == 1:
return Text("少女祈祷中·", style="SIZE60"), 0.2
if nst == 2:
return Text("少女祈祷中··", style="SIZE60"), 0.2
if nst == 3:
return Text("少女祈祷中···", style="SIZE60"), 0.2
image shaonvqidaozhong = DynamicDisplayable(shaonvqidaozhong_func)
这里看到了我是用了style参数,style其实就是我们之前说的可视组件的样式。我对样式并没有很深的应用,主要就是控制文本的排布和字体罢了。
1
2
3
4
style CHOSTYc60:
size 60
outlines [(4, "#000000", 1, 1)]
area(0.35,0.15,0.5,0.7)
screen
screen其实给了用户很高的自由度,来定义游戏内的各个界面。开始界面、暂停界面,也可以自定义一些,比如玩家的笔记本、背包、个人信息等界面。由于我是以做视频为导向的,就没怎么研究过界面语言了。下面是我为数不多的使用screen的地方。
首先是我想把正邪的名字倒过来,这就要改预定义好的对话框的属性了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
transform trans_say_namebox_sj:
yzoom -1.0
xzoom -1.0
transform trans_say_text_sj:
yzoom -1.0
0.8
parallel:
ease 0.5 yzoom 1.0
parallel:
easeout 0.25 yoffset 75
easein 0.25 yoffset 0
# 名字倒置 文本反转
screen say_sj(who, what):
style_prefix "say"
window:
id "window"
if who is not None:
window:
id "namebox"
style "namebox"
text who id "who" at trans_say_namebox_sj
text what id "what" at trans_say_text_sj
if not renpy.variant("small"):
add SideImage() xalign 0.0 yalign 1.0
这里我是直接抄了预定义的say界面,它位于game/rpy/screens.rpy下,我只是给text加了两个transform。
这里也大致可以看出来了,所谓定义一个界面,就是界面里放窗口,窗口里排布一些可视组件罢了,我另一处使用到界面的,就是对战的时候了。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
$ r_hp = 23
$ mmy_hp = 24
screen HLD4_battle_hp:
layer "decorates"
fixed:
xsize 1920
ysize 1080
vbox:
text Text("[r_hp]/23", style="SIZE40"):
xalign 1.0
bar:
value AnimatedValue(r_hp, 23, 0.4)
style "bar_hpI"
xanchor 0.0
xpos 0.02
vbox:
text Text("[mmy_hp]/24", style="SIZE40"):
xalign 0.0
bar:
value AnimatedValue(mmy_hp, 24, 0.4)
style "bar_hp"
xanchor 1.0
xpos 0.98
show screen HLD4_battle_hp
with dissolve
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
image HLDbar_empty:
"item/空生命条.png"
image HLDbar_red:
"item/满生命条.png"
style bar_hpI:
xsize 804
ysize 60
left_bar Frame("HLDbar_empty")
right_bar Frame("HLDbar_red")
bar_invert True
left_gutter 27
right_gutter 18
style bar_hp:
xsize 804
ysize 60
left_bar Frame("HLDbar_red")
right_bar Frame("HLDbar_empty")
left_gutter 27
right_gutter 18
这里的血条要用的非常常用的条(bar),定义好血条的样式后,之后我们只要修改血量,AnimatedValue就会自动帮我们生成条了。参考文档。
我们常用的在screen里的可视部件,在其他游戏里也是常客,比如箱子(hbox & vbox)、格子(grid)、条(hbar & vbar & scrollbar)、按钮(button)、输入框(input)。文档里有很详细的说明如何定义一个可视组件,以条为例,文档里还会有其中可以使用的样式特性,包括条独有的样式特性。像这里的left_gutter和right_gutter就是条左右的沟槽的宽度。
音乐和音效
音乐和音效也是很多小细节的地方,实际上游戏里很多地方我都对了轴,比如卡表算了所有战斗场面前的技能展示,让它配合背景音乐的节奏等等。早先我是在游戏内一点一点实现的,但是经过录制后码率过低,观众反馈后我就基本上放弃了在游戏内直接对轴的想法,而是先定下大概的曲子,录制视频后,直接在视频编辑软件里加音轨,并通过缩放视频的速度(比如太慢了就加个1.02倍速)来对轴。
姑且还是说一下吧,游戏里的音频通道大概有music、sound、voice为默认,也可以自定义通道。但是我基本只使用music和sound。音乐的特点是同时只有一首曲子在播放,播完一首后是循环或者下一首排队播放。而音效则可以同时播放很多,并且一般也不会有什么循环或者排队的需求。
所有的音频靠字符串来定义,并用play、stop、queue来控制:
1
2
3
4
5
define musicZhongGuoQuanFa = "music/中国拳法.mp3"
play music musicZhongGuoQuanFa volume 1.2 # 在music通道播放 音量1.2
queue music musicShoujokisoukyoku # 排队播放
# 中间的代码
stop music fadeout 2.0 # 结束音乐 淡出
放在game/audio文件夹及子文件夹下的音频文件,会被自动加载到游戏中,就像图片一样。顺带一提,音频名会被全部转小写且命名要符合python变量标识符的命名规范。
音量由主音量、混音器音量、通道音量、play语句的音量、音频自身的音量共同控制。
在音乐文件名前加尖括号可以设置音频的属性,主要是裁剪片段、循环和音量等。
1
2
3
4
play music "<loop 1.955 to 91.953>" + musicKyuujigoku # 循环播放某一片段
play music "<from 58.0>" + musicFallFeelFall fadein 2.0 # 从某一点开始播放
play music "<volume 0.5>" + musicZhongGuoQuanFa # 音量0.5
play sound [ "<silence .5>", "boom.opus" ] # 加一段静音 相当于推迟播放